Manipuler des fichiers XML peut être complexe, surtout lorsqu’il s’agit de structurer, stocker et extraire des données efficacement.
Sans une méthode claire, cela peut entraîner des erreurs, des pertes de données, et une gestion inefficace, augmentant les frustrations et les risques d’incohérences.
Cet article vous guide à travers l’utilisation de la bibliothèque ElementTree en Python pour manipuler des fichiers XML de manière simple et structurée, garantissant une gestion optimale de vos données.
Introduction au XML
Définition du format XML
XML (eXtensible Markup Language) est un langage de balisage extensible conçu pour structurer, stocker et transporter des données de manière lisible à la fois par les humains et les machines. Contrairement à HTML, qui sert principalement à créer des pages web, XML se concentre sur la description des données, permettant de définir des balises personnalisées pour structurer l’information de manière hiérarchique. Le format XML prend en charge la validation des données, ce qui garantit leur intégrité et leur conformité aux règles définies, assurant aussi la fiabilité des échanges.

Différences entre HTML et XML
Pour clarifier les distinctions entre les langages de balisage XML et HTML, le tableau ci-dessous présente une comparaison détaillée entre XML (eXtensible Markup Language) et HTML (HyperText Markup Language) :
Caractéristique | XML | HTML |
|---|---|---|
Objectif | Utilisé pour stocker et transporter des données de manière structurée et personnalisable. | Utilisé pour afficher des données sur le web, principalement pour créer des pages web.
|
Balises | Les balises sont définies par l’utilisateur, ce qui permet une grande flexibilité. | Les balises sont prédéfinies par le langage et utilisées pour la mise en forme et la structure des pages web.
|
Syntaxe | Strict, chaque balise doit être fermée correctement et respecter la casse. | Moins stricte, certaines balises n’ont pas besoin d’être fermées et la casse n’est pas sensible.
|
Nesting | Les balises doivent être correctement imbriquées pour être bien formées. | L’imbrication correcte est recommandée, mais certains navigateurs tolèrent des erreurs.
|
Utilisation principale | Stockage, échange de données entre systèmes différents, et configuration. | Création de contenu web avec des éléments comme du texte, des images, des liens, etc.
|
Avantages d'utilisation des formats XML
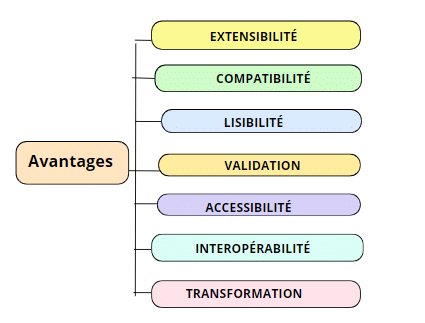
Le format XML est hautement extensible, ce qui signifie qu’il peut être personnalisé pour répondre aux besoins spécifiques d’un projet. Contrairement à d’autres formats de données, XML n’impose pas de structure rigide, permettant ainsi aux utilisateurs de définir leurs propres balises et attributs. Cette flexibilité rend XML approprié pour une variété d’applications, qu’elles soient simples ou complexes.
Le format XML est largement compatible avec de nombreux systèmes et plateformes. Il est conçu pour être lisible à la fois par des humains et des machines, et peut être utilisé dans une grande variété de langages de programmation. Cette compatibilité universelle en fait un choix idéal pour échanger des données entre différentes applications, même celles qui fonctionnent sur des technologies différentes.
Le format XML est intuitivement structuré, ce qui le rend facile à lire et à comprendre, même sans outils spécialisés. Chaque élément de données est clairement délimité par des balises, ce qui permet à toute personne ayant une compréhension de base des formats de balisage de déchiffrer les informations contenues dans un fichier XML. Cette lisibilité améliore la maintenance des fichiers XML, car ils sont facilement interprétables.
XML prend en charge la validation à l’aide de schémas ou de DTD (Document Type Definition). Cela permet de s’assurer que les documents XML respectent une certaine structure ou un ensemble de règles prédéfini. La validation aide à garantir que les données échangées entre systèmes ou applications sont fiables et cohérentes, réduisant ainsi les risques d’erreurs.
L’un des principaux avantages du format XML est son interopérabilité. Il permet à des systèmes disparates de partager des informations de manière fluide. Que ce soit pour des échanges de données entre applications locales ou pour la transmission de données sur Internet, XML facilite l’intégration et la communication entre systèmes hétérogènes.
XML est particulièrement puissant lorsqu’il est associé à des technologies de transformation comme XSLT (Extensible Stylesheet Language Transformations). Cela permet de convertir un document XML dans un autre format, comme du HTML pour une présentation web ou un autre format XML adapté à un système spécifique. Cette capacité à transformer les données offre une grande flexibilité dans leur réutilisation.
Voici une figure qui présente certains des formats dans lesquels un document XML peut être transformé :

Accessibilité
En tant que format basé sur du texte, XML est facilement accessible à tous. Contrairement aux formats binaires, il ne nécessite pas d’outils spécialisés pour être ouvert et édité. De plus, il est bien pris en charge par des éditeurs de texte simples ou des IDE (environnements de développement intégrés), ce qui permet une gestion simple des données, que ce soit pour les développeurs ou pour les utilisateurs non techniques.
Ces avantages font du XML un choix privilégié pour de nombreux scénarios d’échange de données, d’intégration de systèmes, et de structuration de l’information dans divers domaines.
Exploitez la persistance des données en python

Manipulation des fichiers XML avec Python
Création et structuration des fichiers XML en Python
Maintenant que vous avez une compréhension de base de ce qu’est un fichier XML, passons à l’étape suivante : apprendre à stocker des données dans un fichier XML. La manipulation des fichiers XML est assez similaire à celle des fichiers SQL, bien que les structures et les bibliothèques utilisées diffèrent. En Python, une bibliothèque couramment utilisée pour travailler avec les fichiers XML est xml.etree.ElementTree. Cette bibliothèque facilite la création, la manipulation et l’écriture des données XML.
Utilisation de la Bibliothèque ElementTree en Python
Nous allons découvrir comment utiliser la bibliothèque ElementTree en Python pour créer et manipuler des structures XML. ElementTree, qui fait partie de la bibliothèque standard de Python, propose des outils puissants pour travailler avec des documents XML.
Nous commencerons par importer cette bibliothèque, puis nous créerons un fichier XML en définissant une hiérarchie d’éléments et de sous-éléments, en utilisant notamment des balises comme root et person, qui constitueront la structure de base de notre fichier XML. Toutes ces étapes sont expliquées en détail dans ce qui suit :
Importation de la bibliothèque
Pour commencer, nous devons importer la bibliothèque ElementTree de la manière suivante, en utilisant l’alias ET pour simplifier les références ultérieures dans le code :
import xml.etree.ElementTree as ET
Création de la structure XML
Nous allons commencer par créer l’élément racine, ou "root", de notre fichier XML. Cela servira de point de départ pour toute la hiérarchie XML :
root = ET.Element("root")
Ensuite, nous ajoutons un sous-élément nommé person, qui représentera un enregistrement ou une entrée dans notre fichier XML :
person = ET.SubElement(root, "person")
Ajout de sous-éléments avec des données
Pour chaque personne, nous pouvons ajouter des sous-éléments supplémentaires pour stocker des informations spécifiques comme le nom, le prénom et l’âge. Voici comment ajouter ces sous-éléments :
ET.SubElement(person, "nom").text = "Dupont"
ET.SubElement(person, "prenom").text = "Jean"
ET.SubElement(person, "age").text = "30"
Ces lignes de code créent des sous-éléments sous l’élément person et y ajoutent des valeurs textuelles.
Écriture de l’arborescence XML dans un fichier
Une fois que nous avons défini toute la structure de notre document XML, il est temps de l’écrire dans un fichier. Nous utilisons pour cela la méthode ElementTree pour créer un arbre à partir de notre élément racine, puis la méthode write() pour enregistrer cet arbre dans un fichier XML :
tree = ET.ElementTree(root)
tree.write("personne.xml")
En enregistrant et en exécutant ce script, le fichier personne.xml contiendra la structure suivante :
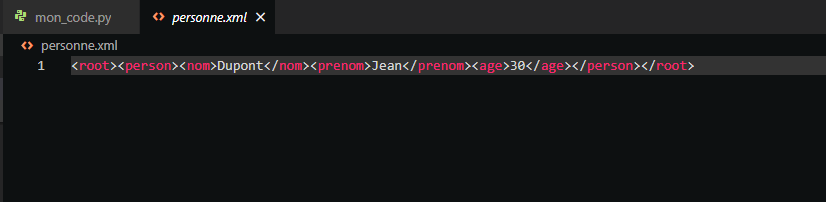

Visualisation des fichiers XML en Python
En ouvrant ce fichier XML avec un éditeur de texte ou un explorateur de fichiers compatible XML, vous verrez la structure hiérarchique des données telle que définie dans le code. Cela vous permet de stocker et organiser vos données de manière structurée et lisible, similaire à la manipulation des données dans des bases de données SQL, mais avec une flexibilité supplémentaire offerte par le format XML.

Lecture et parcours des données XML en Python
Après avoir vu comment écrire des données dans un fichier XML, nous allons maintenant explorer comment lire et parcourir ces données. Pour cela, nous utiliserons la fonction ET.parse() de la bibliothèque ElementTree afin de parser le fichier XML, c’est à dire analyser le fichier XML et récupérer les données qu’il contient.
Pour commencer, nous devons parser le fichier XML avec ET.parse(). Cette fonction prend en argument le nom du fichier XML et retourne un objet ElementTree :
tree = ET.parse('output.xml')
Une fois le fichier XML parsé, nous devons récupérer l’élément racine du document pour pouvoir accéder à l’ensemble de la structure XML. Cela se fait à l’aide de l’instruction suivante :
root = tree.getroot()
L’objet root représente l’élément racine du fichier XML et sert de point de départ pour naviguer dans l’arborescence des éléments.
Pour parcourir les éléments dans le fichier XML, nous utilisons une boucle for. Par exemple, si nous souhaitons parcourir tous les éléments person dans le fichier XML, nous pouvons utiliser la méthode findall() :
for person in root.findall("person"):
nom = person.find("nom").text
prenom = person.find("prenom").text
age = person.find("age").text
print(f"Nom: {nom}, Prénom: {prenom}, Âge: {age}")
Dans cet exemple, la méthode findall("person") cherche tous les éléments person sous l’élément racine. Ensuite, pour chaque élément person, nous utilisons find() pour accéder aux sous-éléments nom, prenom et age, et nous récupérons leur contenu textuel.
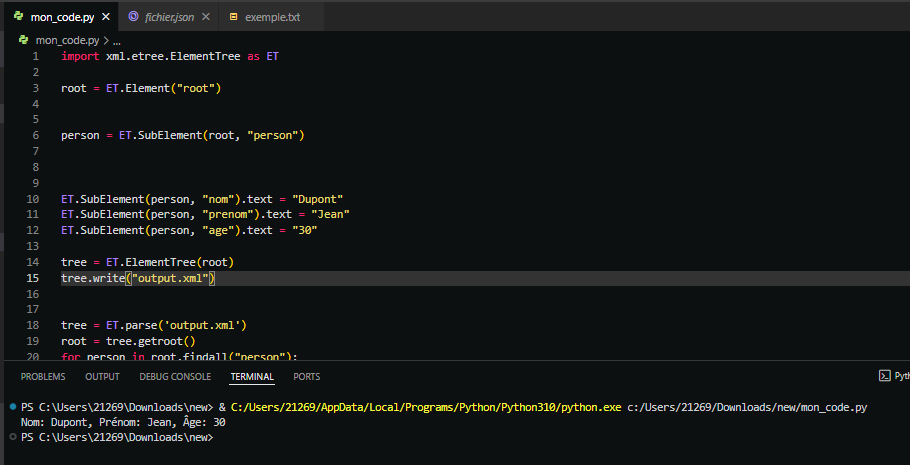
Avec ces données extraites, vous pouvez personnaliser l’affichage en Python selon vos besoins. Voici un exemple complet qui lit le fichier XML, extrait les données des éléments person, et affiche ces données d’une manière formatée :
En exécutant ce script, le programme affichera les informations de chaque person dans le fichier XML de manière lisible et organisée. Voici le résultat d’exécution de ce programme :
Formez-vous gratuitement avec Alphorm !
Maîtrisez les compétences clés en IT grâce à nos formations gratuites et accélérez votre carrière dès aujourd'hui. Découvrez des cours variés pour tous les niveaux !

Conclusion
La manipulation des fichiers XML en Python permet de structurer, lire et modifier des données de façon efficace. Grâce à des bibliothèques comme ElementTree, Python offre une grande flexibilité dans le traitement des fichiers XML. Cette solution est idéale pour gérer des données complexes tout en restant compatible avec divers systèmes.