Les développeurs rencontrent souvent des difficultés pour gérer efficacement les bases de données relationnelles avec SQLite, surtout lors de la manipulation des requêtes complexes.
Sans une gestion optimisée des requêtes et des jointures, les performances peuvent en pâtir, entraînant des ralentissements et une mauvaise organisation des données.
Dans cet article, découvrez comment utiliser SQLite avec Python pour manipuler et optimiser vos bases de données, sécuriser vos requêtes, et exploiter les jointures pour une gestion plus fluide et performante de vos projets.
Base de données relationnelle en Python
Qu'est-ce qu'une base de données relationnelle ?
Une base de données relationnelle est un type de base de données qui stocke les informations sous forme de tables composées de lignes et de colonnes. Elle facilite les relations entre ces tables, par exemple, on peut avoir une table « clients » avec des champs comme « id », « nom », « prénom », et « code postal », et une autre table « commandes » contenant « id », « commande » et « HT ». Pour relier ces deux tables, notamment pour associer les commandes aux clients, on utilise des bases de données relationnelles, et plus précisément ce qu’on appelle les jointures.

Historique du langage SQL
SQL, acronyme de Structured Query Language (langage de requête structuré), est un langage de programmation standardisé utilisé pour gérer et manipuler les bases de données relationnelles. Il a été initialement développé par IBM dans les années 1970 sous le nom de SEQUEL (Structured English Query Language) pour interagir avec le prototype de système de gestion de bases de données relationnelles appelé System R, basé sur le modèle relationnel proposé par Edgar F. Codd.
L'évolution du langage SQL
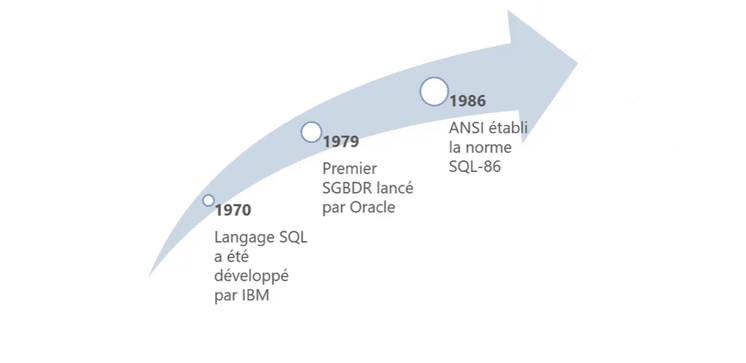
SQL a connu plusieurs étapes clés au cours de son développement, qui ont influencé son évolution et son adoption à grande échelle. Voici les étapes les plus marquantes de son histoire :
- 1970 : IBM a développé SQL dans le cadre du projet System R, un prototype de SGBDR (Système de Gestion de Bases de Données Relationnelles) conçu pour valider le modèle relationnel de Codd et explorer l’utilisation de SQL pour la gestion des données.
- 1979 : Oracle a lancé le premier SGBDR commercial utilisant SQL. Cet événement a marqué un tournant dans l’histoire des bases de données relationnelles, car il a permis une adoption plus large du langage SQL dans l’industrie, rendant les bases de données relationnelles accessibles aux entreprises et facilitant leur gestion.
- 1986 : SQL a été standardisé par l’ANSI (American National Standards Institute) sous le nom de SQL-86. Cette standardisation a établi SQL comme le langage standard pour la gestion des bases de données relationnelles, garantissant une uniformité et une portabilité accrues des applications à travers différents systèmes de bases de données.
Ces étapes clés ont jalonné l’évolution de SQL, depuis sa conception initiale jusqu’à sa reconnaissance en tant que norme internationale, consolidant son rôle essentiel dans la gestion des bases de données relationnelles à l’échelle mondiale.
Fonctionnement des SGBDR (Systèmes de Gestion de Bases de Données Relationnelles)
Les SGBDR utilisent le langage SQL, qui est un langage de programmation déclaratif. Cela signifie que l’utilisateur décrit ce qu’il souhaite accomplir sans avoir à spécifier comment l’opération doit être réalisée. Par exemple, pour effectuer une requête, l’utilisateur tape la commande SQL sur le clavier, en indiquant l’opération souhaitée (comme sélectionner, insérer ou mettre à jour des données). Cette requête est ensuite envoyée au SGBDR, qui se charge de l’exécuter et de renvoyer les résultats appropriés.
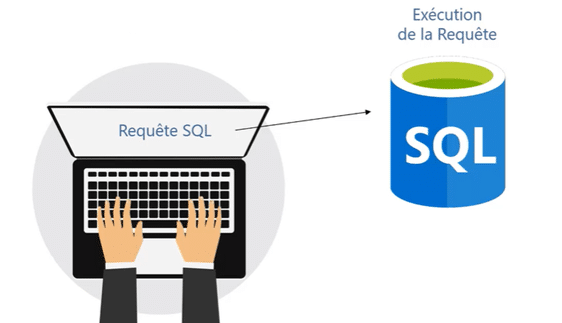
Dans un SGBDR, le fonctionnement est divisé en plusieurs étapes clés :
- Écriture de la Requête : L’utilisateur écrit une requête SQL pour définir l’opération à effectuer sur la base de données, comme récupérer des données, ajouter des enregistrements, ou modifier des informations existantes.
- Envoi de la Requête : La requête est envoyée au moteur du SGBDR, qui interprète le code SQL.
- Exécution par le SGBDR : Le moteur du SGBDR analyse et optimise la requête, puis l’exécute en suivant le meilleur chemin d’accès aux données. Le SGBDR s’occupe de tous les aspects complexes de l’exécution, tels que la gestion des index, l’accès aux données, et la maintenance de l’intégrité référentielle.
- Résultat : Le résultat de la requête est retourné à l’utilisateur, affichant les données demandées ou confirmant la modification ou insertion effectuée.
Ce fonctionnement en mode déclaratif simplifie la gestion des bases de données, car l’utilisateur n’a pas besoin de connaître les détails techniques sur la façon dont les données sont manipulées en interne. Le SGBDR prend en charge ces détails, optimisant l’exécution des requêtes pour assurer des performances efficaces et une utilisation cohérente des ressources système.
Les composants d'une base de données SQL
Dans une base de données relationnelle, les données sont organisées en tables, ce qui permet une structure claire et des relations définies entre les différentes entités. Chaque table représente une entité spécifique du système d’information, et les données sont stockées de manière à minimiser la redondance tout en maximisant l’intégrité des requêtes. Pour mieux comprendre la structure d’une base de données relationnelle, il est essentiel de connaître ses principaux composants comme il est montré dans la figure suivante :
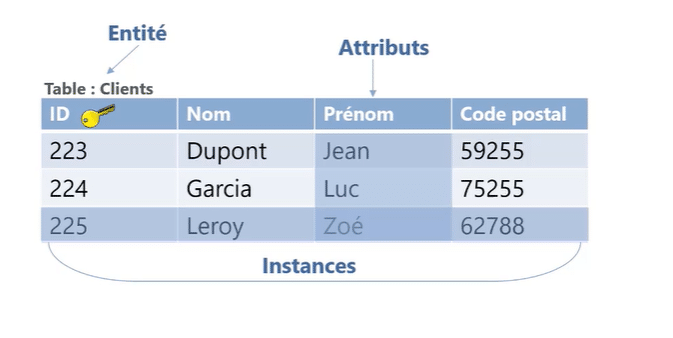
- Entité : Dans une base de données relationnelle, chaque table est considérée comme une entité.
- Attribut : Les colonnes d’une table sont appelées attributs.
- Instance : Les lignes d’une table représentent des instances de l’entité, par exemple les informations spécifiques d’un client.
- Clés : Les tables peuvent être reliées entre elles à l’aide de clés primaires ou étrangères.
Avantage des bases de données relationnelles en Python :
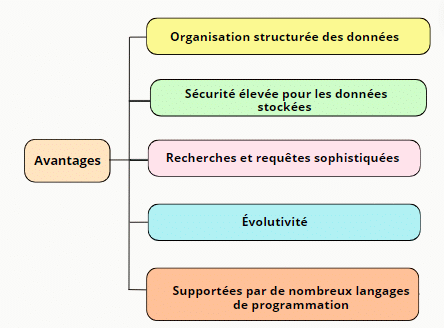
Les bases de données relationnelles, comme SQL, offrent plusieurs avantages importants à savoir :
- Organisation structurée des données :
Les données sont organisées sous forme de tables, permettant une gestion claire et structurée. Chaque table est composée de lignes et de colonnes, où les colonnes représentent des attributs et les lignes représentent des enregistrements. Pour mieux comprendre cette structure voici un exemple explicatif :
ID Étudiant | Nom | Prénom | Âge | Filière |
|---|---|---|---|---|
001 | Dupont | Marie | 20 | Intelligence Artificielle |
002 | Martin | Jean | 22 | Informatique
|
003 | Durand | Alice | 21 | Mathématiques |
Dans le tableau si dessus, chaque ligne représente un enregistrement d’un étudiant et chaque colonne représente un attribut : ID Étudiant, Nom, Prénom, Âge, et Filière. Cette structure facilite le stockage, la manipulation et la récupération des données.
- Sécurité élevée pour les données stockées :
Les bases de données relationnelles offrent des mécanismes robustes de sécurité, incluant des contrôles d’accès, des permissions d’utilisateur, et des fonctionnalités d’audit. Cela garantit que seules les personnes autorisées peuvent accéder ou modifier les données, protégeant ainsi les informations sensibles.
- Recherches et requêtes sophistiquées :
Grâce au langage SQL, les bases de données relationnelles permettent d’exécuter des requêtes complexes pour extraire des données spécifiques, effectuer des calculs, et générer des rapports. Les utilisateurs peuvent facilement filtrer, trier et agréger les données pour répondre à des besoins d’analyse précis.
- Évolutivité :
Les bases de données relationnelles sont conçues pour être évolutives, c’est-à-dire qu’elles peuvent croître en taille et en capacité avec l’augmentation des données et des utilisateurs sans perdre en performance. Cela est crucial pour les entreprises en expansion qui doivent gérer de plus en plus de données au fil du temps.
- Supportées par de nombreux langages de programmation :
Les bases de données relationnelles sont compatibles avec une large gamme de langages de programmation (comme Python, Java, C#, etc.), permettant aux développeurs d’intégrer facilement des fonctionnalités de gestion de données dans leurs applications.
Ces avantages rendent les bases de données relationnelles particulièrement adaptées pour les projets nécessitant une gestion rigoureuse des données, une sécurité renforcée, et des performances fiables à long terme.
Exploitez la persistance des données en python

Ressources recommandées pour maîtriser SQL en Python
Pour maîtriser le langage SQL, je vous recommande tout d’abord le site web sql.sh, qui est une ressource interactive et très utile pour acquérir des compétences pratiques. En complément, je vous suggère également la formation complète proposée par Alphorm intitulée « Le Guide Complet du Langage SQL ». Cette formation, d’une durée de 12 heures, couvre de manière exhaustive tous les aspects essentiels du langage SQL, vous permettant ainsi de développer une compréhension approfondie et solide de ce langage.
Le module sqlite3 en Python
Qu'est-ce que le module sqlite3 en Python ?
Le module sqlite3 est une bibliothèque intégrée dans Python qui permet de manipuler des bases de données SQLite directement à partir de votre code Python. Il fournit une interface simple et cohérente pour interagir avec des bases de données SQLite, offrant des fonctionnalités telles que la création, la modification, et la gestion de bases de données, ainsi que l’exécution de requêtes SQL.

Utilisation du module sqlite3 pour les bases de données SQLite en Python
Le module sqlite3 en Python permet d’interagir facilement avec les bases de données SQLite. Voici ce qu’il vous permet de faire :
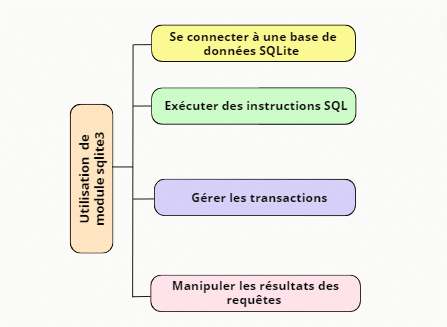
- Se connecter à une base de données SQLite : Créer une nouvelle base de données ou se connecter à une base existante.
- Exécuter des instructions SQL : Inclure des commandes pour créer des tables, insérer des données, interroger et mettre à jour les données.
- Gérer les transactions : Commencer, valider, et annuler des transactions.
- Manipuler les résultats des requêtes : Accéder aux résultats des requêtes SQL de manière structurée.
Il est particulièrement utile pour les applications locales et les projets qui nécessitent une gestion de base de données simple sans avoir besoin d’un serveur de base de données complexe.
Ouvrir une connexion à une base de données SQLite en Python
Pour ouvrir une connexion à une base de données SQLite en Python, vous pouvez utiliser deux méthodes principales. Voici comment procéder :
- Utiliser la méthode connect du module sqlite3 :
import sqlite3
conn = sqlite3.connect("nom_de_la_base_de_donnees.db")
Cette méthode crée une connexion à une base de données SQLite spécifiée par le nom du fichier (dans cet exemple, « nom_de_la_base_de_donnees.db »). Si le fichier n’existe pas, SQLite le crée automatiquement. Vous pouvez ensuite utiliser l’objet conn pour interagir avec la base de données, comme exécuter des requêtes SQL, gérer les transactions, etc.
- Utiliser un gestionnaire de contexte avec la méthode connect
import sqlite3
with sqlite3.connect("nom_de_la_base_de_donnees.db") as conn:
# Utilisez `conn` ici pour exécuter des requêtes
En utilisant un gestionnaire de contexte (with), la connexion est automatiquement fermée à la fin du bloc, même si une erreur se produit. Cela permet de garantir que les ressources sont correctement libérées et que la connexion est bien fermée après l’utilisation.
Les deux méthodes vous permettent d’ouvrir une connexion à une base de données SQLite, mais la deuxième méthode est souvent préférée pour sa gestion automatique des ressources.
Manipuler des bases de données SQLite avec sqlite3
Pour manipuler des bases de données en utilisant le module sqlite3 en Python, voici les étapes complètes :
Avant de commencer, vous devez importer le module sqlite3 dans votre script Python.
import sqlite3
Vous devez établir une connexion à une base de données SQLite. Vous pouvez créer une nouvelle base de données ou vous connecter à une base de données existante en spécifiant le nom du fichier de base de données.
conn = sqlite3.connect('nom_de_la_base_de_donnees.db')
Un curseur est utilisé pour exécuter des requêtes SQL et interagir avec la base de données.
cursor = conn.cursor()
- Exécuter des Requêtes SQL
Vous pouvez exécuter des instructions SQL en utilisant la méthode execute du curseur. Voici quelques exemples courants :
Créer une Table :
cursor.execute('''
CREATE TABLE IF NOT EXISTS utilisateurs (
id INTEGER PRIMARY KEY,
nom TEXT NOT NULL,
age INTEGER
)
''')
Insérer des Données :
cursor.execute('''
INSERT INTO utilisateurs (nom, age) VALUES ('Alice', 30))
Si vous effectuez des modifications sur la base de données, vous devez valider les transactions en utilisant la méthode commit.
conn.commit()
Une fois que vous avez terminé vos opérations, vous devez fermer la connexion à la base de données pour libérer les ressources.
conn.close()
Installation de SQLite sur votre système en Python
Toutefois, vous pouvez également gérer et manipuler vos bases de données SQLite à l’aide de logiciels indépendants de Python, ce qui vous offre davantage de fonctionnalités et de flexibilité. Parmi ces outils, nous vous recommandons DB Browser for SQLite. Ce logiciel vous permet de visualiser, modifier et interagir avec vos bases de données SQLite de manière graphique et intuitive.
Pour installer et utiliser SQLite, suivez ces étapes essentielles. Commencez par télécharger le logiciel SQLite depuis le site officiel SQLite Downloads. Selon votre système d’exploitation, choisissez le fichier approprié : un fichier ZIP pour Windows, un fichier .dmg pour macOS, ou utilisez le gestionnaire de paquets pour Linux. Une fois téléchargé, décompressez le fichier ZIP sur Windows et ajoutez le répertoire contenant sqlite3.exe à votre variable d’environnement PATH.

Maintenant vous pouvez créer et gérer des bases de données SQLite directement depuis la ligne de commande ou utiliser des outils graphiques tels que DB Browser for SQLite pour une interface plus conviviale. Ces étapes vous permettront de configurer et d’utiliser SQLite efficacement pour vos projets de base de données.

Créer une table avec SQLite en Python
Pour créer une table en Python en utilisant SQLite, vous pouvez suivre ces étapes. Vous pouvez également utiliser des ressources en ligne comme SQL.sh pour obtenir des exemples de code SQL. Voici un guide structuré :
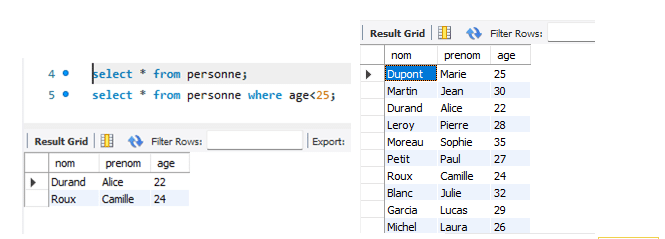
Visitez le site SQL.sh (ou toute autre ressource de tutoriels SQL) et recherchez l’exemple de code pour créer une table. Par exemple, recherchez « create table » pour obtenir des instructions sur la structure de la commande SQL.
Maintenant, copiez le code trouvé dans la section de requêtes pour l’exécuter. Voici le code que nous avons trouvé :
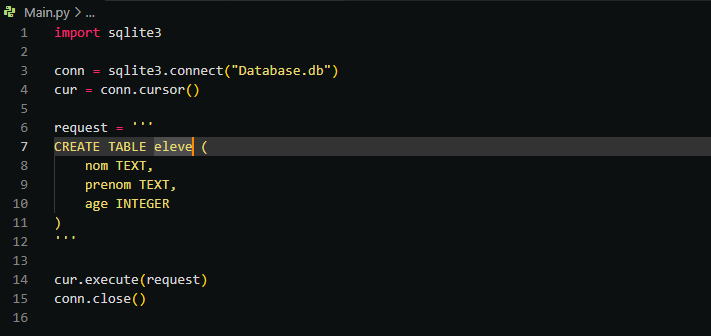
En exécutant ce même code une deuxième fois, une erreur sera déclenchée, comme indiqué dans la figure suivante.
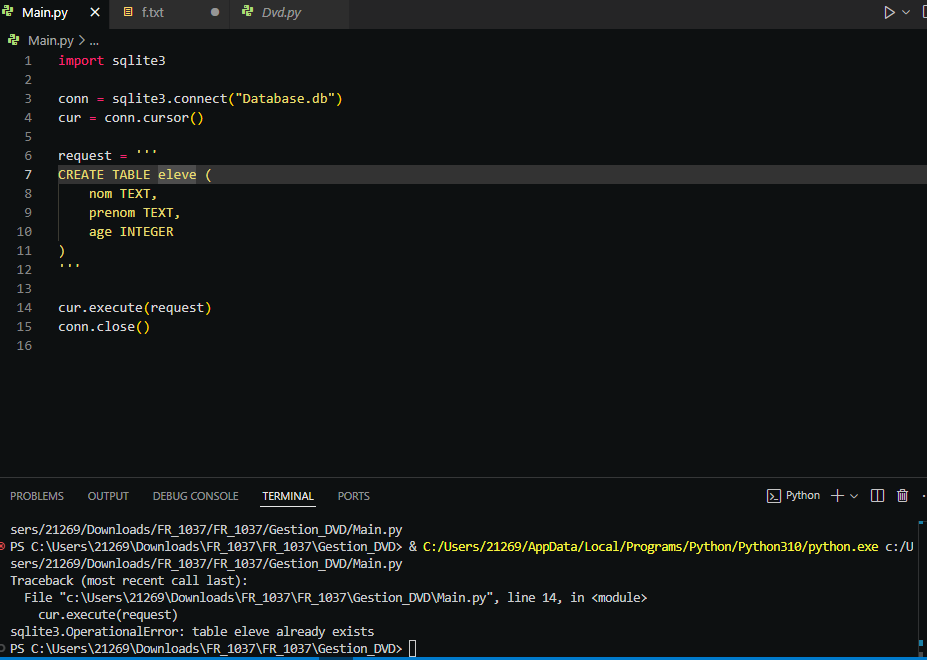
Pour éviter l’erreur qui se produit lorsqu’on tente de créer une table qui existe déjà, vous pouvez modifier la commande SQL pour inclure la clause IF NOT EXISTS. Cette condition permet à la base de données de vérifier si la table existe déjà avant de tenter de la créer, évitant ainsi des erreurs dues à des tentatives de création de tables redondantes.
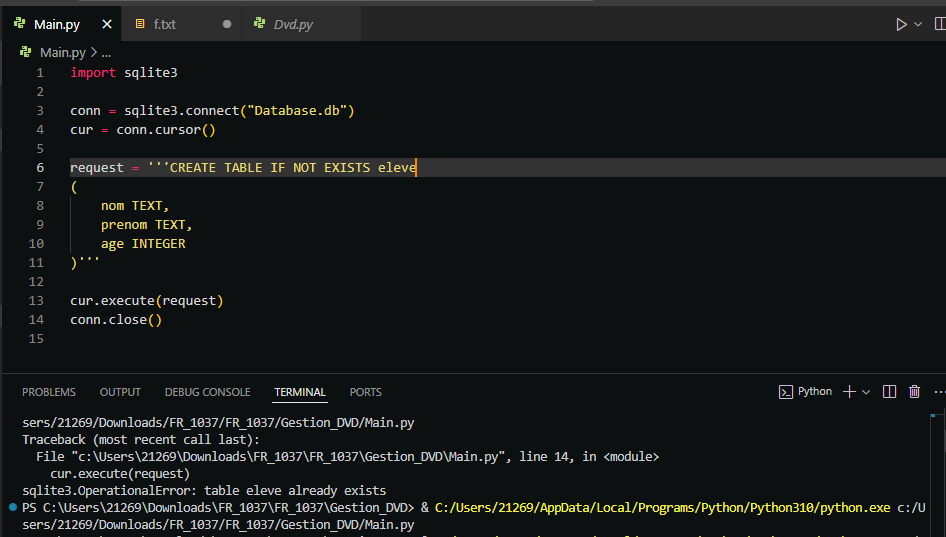
Les syntaxes SQL
Ajouter des données dans une table avec SQL
Maintenant que nous avons créé une table avec trois attributs : nom, prénom et âge, nous allons vous montrer comment ajouter des données dans cette table. Pour insérer des données, nous utiliserons la commande SQL INSERT INTO, qui permet d’ajouter de nouvelles entrées dans la table.
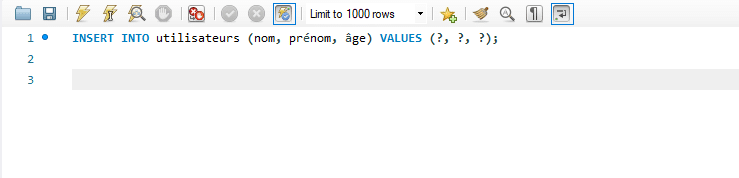
Dans cette requête :
INSERT INTO utilisateurs : Indique la table dans laquelle vous souhaitez insérer les données.
(nom, prénom, âge) : Liste les attributs pour lesquels vous fournirez des valeurs.
VALUES (?, ?, ?) : Spécifie les emplacements où les valeurs seront insérées. Les points d’interrogation (?) sont des paramètres qui seront remplacés par les valeurs réelles lors de l’exécution de la requête.
- Exécuter la Requête dans Python : Utilisez le module sqlite3 en Python pour exécuter la requête d’insertion. Voici comment procéder :
import sqlite3
# Connexion à la base de données
conn = sqlite3.connect('nom_de_la_base_de_donnees.db')
cursor = conn.cursor()
# Requête SQL pour insérer des données
cursor.execute('''
INSERT INTO utilisateurs (nom, prénom, âge) VALUES ('Dupont', 'Jean', 28)
''')
# Valider les modifications
conn.commit()
# Fermer la connexion
conn.close()
Dans ce code, comme expliqué dans les sections précédentes :
cursor.execute() : Exécute la requête SQL avec les valeurs spécifiées. Les valeurs ‘Dupont’, ‘Jean’, et 28 seront insérées dans les colonnes nom, prénom, et âge respectivement.
conn.commit() : Valide la transaction pour que les modifications soient enregistrées dans la base de données.
conn.close() : Ferme la connexion à la base de données pour libérer les ressources.
Lire les données d'une table SQL
De la même manière que nous avons importé le module sqlite3, établi la connexion et créé le curseur, nous allons maintenant lire le contenu d’une table. Pour ce faire, nous utiliserons la commande SQL SELECT dans notre requête et l’exécuterons. Vous pouvez utiliser la méthode fetchall() pour récupérer toutes les lignes ou fetchone() pour récupérer une seule ligne à la fois. Voici comment procéder :
- Importer le Module et Créer la Connexion :
De la même manière que précédemment, nous importons le module et créons une connexion, comme illustré dans le code suivant.
import sqlite3
# Connexion à la base de données
conn = sqlite3.connect('nom_de_la_base_de_donnees.db')
cursor = conn.cursor()
- Lire le Contenu de la Table avec SELECT :
Nous utilisons l’instruction SELECT pour interroger et lire les données de la table. Le code ci-dessous montre comment effectuer cette opération pour récupérer et afficher le contenu de la table.
cursor.execute('''
SELECT * FROM utilisateurs
''')
# Récupérer toutes les lignes
rows = cursor.fetchall()
# Afficher les résultats
for row in rows:
print(row)
Comme vous l’avez vu dans le code ci-dessus, la fonction fetchall() est utilisée pour récupérer toutes les lignes retournées par la requête SELECT. Cette méthode stocke les résultats dans une liste, ce qui permet de manipuler facilement toutes les données en une seule opération.
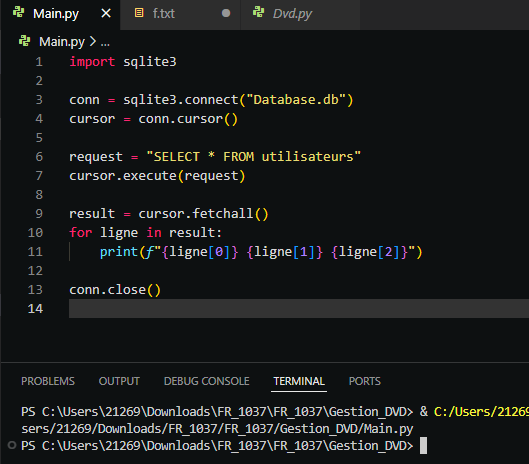
Si vous souhaitez une approche plus progressive, vous pouvez également utiliser la méthode fetchone(), qui permet de récupérer une seule ligne à la fois. En appelant fetchone() plusieurs fois, vous pouvez parcourir les lignes une par une, ce qui peut être utile pour traiter les données de manière séquentielle.
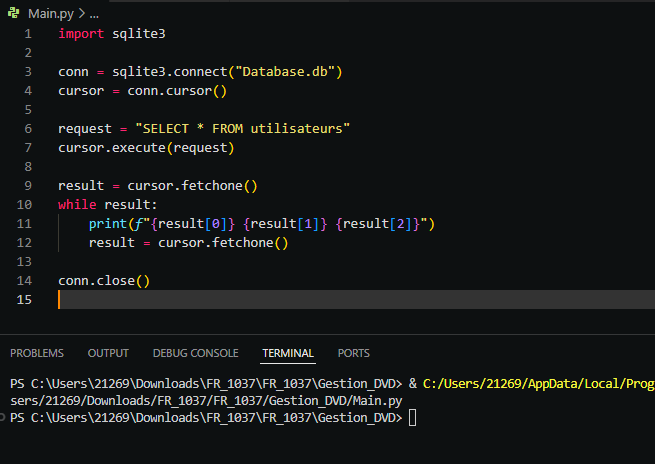
Ces deux méthodes offrent une grande flexibilité pour lire et afficher les données stockées dans votre table SQLite, adaptées à vos besoins spécifiques.
Modifier des données dans une table SQLite en Python
Lors de la manipulation de bases de données en Python, il est fréquent de devoir modifier les données contenues dans une table. Nous avons déjà abordé comment lire, sélectionner et ajouter des enregistrements dans une base de données SQLite. Maintenant, nous allons voir comment mettre à jour les données existantes dans une table en utilisant la commande SQL UPDATE.
Nous avons déjà créé une base de données appelée database.db ainsi qu’une table appelée cursus. Afin de modifier les données d’une table, nous allons utiliser maintenant la commande UPDATE, associée à SET pour définir les nouvelles valeurs et à la clause WHERE pour spécifier les lignes à modifier. Voici la structure générale d’une requête de mise à jour :

Imaginons que nous souhaitons mettre à jour le prénom d’un étudiant dans la table cursus. Voici comment procéder avec Python :
import sqlite3
# Connexion à la base de données
conn = sqlite3.connect('database.db')
cursor = conn.cursor()
# Mise à jour du prénom de l'étudiant dont l'identifiant est 1
cursor.execute("""
UPDATE cursus
SET prenom = 'NouveauPrenom'
WHERE id = 1;
""")
# Validation des modifications
conn.commit()
# Affichage du nombre de lignes modifiées
print(f"Nombre de lignes modifiées : {cursor.rowcount}")
# Fermeture de la connexion
conn.close()
Points clés à noter pour la modification des données
- Mise à jour de plusieurs colonnes : Vous pouvez modifier plusieurs colonnes en même temps en les séparant par des virgules dans la clause
SET. Par exemple :
UPDATE cursus
SET prenom = 'NouveauPrenom', nom = 'NouveauNom'
WHERE id = 1;
- Modification de toutes les lignes : Si vous omettez la clause WHERE, toutes les lignes de la table seront modifiées. Soyez donc prudent lors de l’utilisation de UPDATE sans condition.
Supprimer des données dans une table SQLite avec Python
Après avoir appris à lire, écrire et modifier les données dans une base de données SQLite, nous allons maintenant découvrir comment supprimer des lignes d’une table en utilisant Python. La suppression de données dans une table est réalisée à l’aide de la commande DELETE FROM, associée à la clause WHERE pour spécifier les lignes à supprimer. Voici la syntaxe générale :
DELETE FROM nom_de_la_table
WHERE condition;
Supposons que nous souhaitons supprimer un étudiant dont l’identifiant est 1 de la table cursus. Voici comment procéder en Python :
import sqlite3
# Connexion à la base de données
conn = sqlite3.connect('database.db')
cursor = conn.cursor()
# Suppression de l'étudiant avec l'ID 1
cursor.execute("""
DELETE FROM cursus
WHERE id = 1;
""")
# Validation des modifications
conn.commit()
# Affichage du nombre de lignes supprimées
print(f"Nombre de lignes supprimées : {cursor.rowcount}")
# Fermeture de la connexion
conn.close()
Points importants à noter lors de la suppression des données
Suppression de plusieurs lignes : Pour supprimer plusieurs lignes en une seule commande, vous pouvez spécifier une condition dans la clause WHERE qui correspond à plusieurs lignes. Par exemple, pour supprimer tous les étudiants d’une certaine classe :
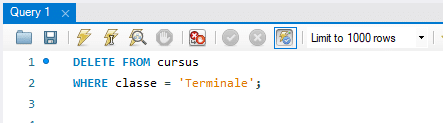
Suppression de toutes les lignes : Si vous souhaitez supprimer toutes les lignes d’une table, utilisez la commande DELETE sans la clause WHERE :
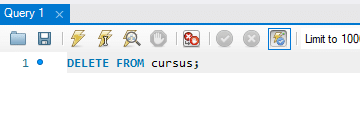
Cela vide la table, mais la table elle-même continue d’exister dans la base de données.
Suppression définitive de la table : Si votre objectif est de supprimer entièrement une table, y compris sa structure, utilisez la commande DROP TABLE au lieu de DELETE. Voici comment faire :
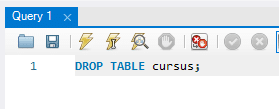
Cette commande supprime la table et toutes ses données de manière permanente.
Méthode rowcount en Python
La méthode rowcount de l’objet cursor permet de connaître le nombre de lignes affectées par une requête SQL, telle que DELETE, INSERT, UPDATE, ou SELECT. Cela est particulièrement utile pour vérifier l’effet de votre requête SQL et s’assurer que les opérations ont été effectuées comme prévu.
# Supposons que nous avons exécuté une commande DELETE
cursor.execute("DELETE FROM ma_table WHERE condition")
# Afficher le nombre de lignes supprimées
print(f"Nombre d'instances supprimées : {cursor.rowcount}")
Dans cet exemple, cursor.rowcount retourne le nombre de lignes supprimées par la commande DELETE. Si aucune ligne n’est supprimée, rowcount retournera 0. Cela permet de vérifier facilement l’impact de la requête sur la base de données.
Utiliser les jointures en SQL et Python
Comment utiliser les jointures en SQL
Le mot-clé JOIN en SQL est utilisé pour combiner des lignes de deux ou plusieurs tables basées sur une colonne commune. Par défaut, lorsque vous utilisez simplement JOIN sans spécifier le type, cela équivaut à un INNER JOIN. Le JOIN ne retourne que les lignes pour lesquelles il y a des correspondances dans les tables impliquées dans la jointure.
Imaginons que nous ayons deux tables : client et commande. Nous souhaitons combiner ces tables pour afficher les informations des clients et leurs commandes. Voici comment utiliser JOIN :
Table client :
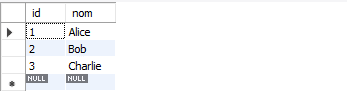
Table commande :
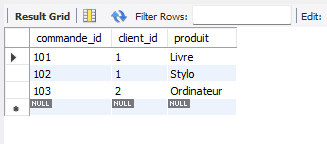
Requête SQL :
Voici la requête SQL permettant de réaliser une jointure entre les deux tables :
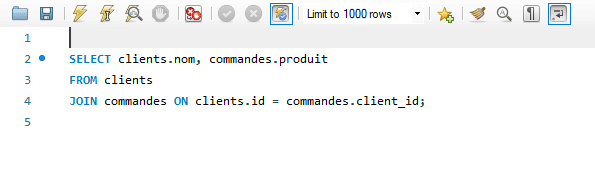
Voici le résultat de l’exécution de la requête SQL :
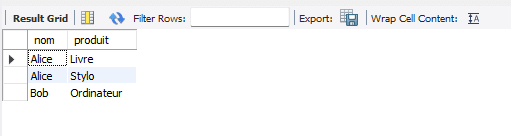
Ce code combine les tables client et commande sur la base de la colonne id dans client et client_id dans commande, renvoyant uniquement les lignes pour lesquelles il y a une correspondance dans les deux tables.
Les différents types de jointures SQL
Les jointures sont un outil puissant pour interroger et manipuler les données, permettant de combiner des informations provenant de plusieurs sources dans une base de données. Voici un aperçu des différents types de jointures en SQL, avec des descriptions et des exemples :
Type de Jointure | Description | Exemple |
|---|---|---|
INNER JOIN | Retourne uniquement les lignes qui ont des correspondances dans les deux tables. | SELECT * FROM A INNER JOIN B ON A.id = B.id;
|
LEFT JOIN | Retourne toutes les lignes de la table de gauche, et les lignes correspondantes de la table de droite. Si aucune correspondance n’est trouvée, les valeurs de la table de droite sont NULL. | SELECT * FROM A LEFT JOIN B ON A.id = B.id;
|
RIGHT JOIN | Retourne toutes les lignes de la table de droite, et les lignes correspondantes de la table de gauche. Si aucune correspondance n’est trouvée, les valeurs de la table de gauche sont NULL. | SELECT * FROM A RIGHT JOIN B ON A.id = B.id;
|
Explication des Différents Types de Jointures
- INNER JOIN :
C’est le type de jointure par défaut. Il est utilisé pour récupérer les lignes qui ont des correspondances dans les deux tables. Les lignes sans correspondance dans l’une ou l’autre des tables sont exclues.
Exemple : Pour obtenir seulement les clients qui ont passé des commandes.
- LEFT JOIN :
Cette jointure retourne toutes les lignes de la table de gauche (client), et les lignes correspondantes de la table de droite (commande). Si aucune correspondance n’est trouvée, les résultats de la table de droite sont NULL.
Exemple : Pour obtenir tous les clients, même ceux qui n’ont pas passé de commandes.
- RIGHT JOIN :
L’inverse du LEFT JOIN. Il retourne toutes les lignes de la table de droite (commande), et les correspondances de la table de gauche (client). Si aucune correspondance n’est trouvée, les résultats de la table de gauche sont NULL.
Exemple : Pour obtenir toutes les commandes, même celles passées par des clients qui ne sont plus dans la table client.
Utiliser des jointures avec sqlite3 en Python
Pour utiliser les jointures en Python à l’aide du module sqlite3, vous devez suivre les étapes suivantes :
Création de la Base de Données et des Tables
D’abord, vous devez créer une base de données et définir vos tables. Par exemple, nous avons deux tables : clients et commandes.
import sqlite3
# Connexion à une base de données SQLite (en mémoire pour cet exemple)
conn = sqlite3.connect(':memory:')
cursor = conn.cursor()
# Création des tables
cursor.execute('''
CREATE TABLE clients (
id INTEGER PRIMARY KEY,
nom TEXT
);
''')
cursor.execute('''
CREATE TABLE commandes (
commande_id INTEGER PRIMARY KEY,
client_id INTEGER,
produit TEXT
);
''')
Insertion des Données
Maintenant, vous pouvez insérer des données dans les tables nouvellement créées.
# Insertion des données dans les tables
cursor.executemany('INSERT INTO clients (id, nom) VALUES (?, ?);', [
(1, 'Alice'),
(2, 'Bob'),
(3, 'Charlie')
])
cursor.executemany('INSERT INTO commandes (commande_id, client_id, produit) VALUES (?, ?, ?);', [
(101, 1, 'Livre'),
(102, 1, 'Stylo'),
(103, 2, 'Ordinateur')
])
Exécution des Requêtes avec Jointures
Utilisez des requêtes SQL pour effectuer des jointures entre les tables. Vous pouvez faire différents types de jointures comme INNER JOIN, LEFT JOIN, etc.
# Exécution d'une requête INNER JOIN pour combiner les données
cursor.execute('''
SELECT clients.nom, commandes.produit
FROM clients
INNER JOIN commandes ON clients.id = commandes.client_id;
''')
# Affichage des résultats
for row in cursor.fetchall():
print(row)
Ce code exécutera une jointure interne (INNER JOIN) qui renvoie les noms des clients associés aux produits qu’ils ont commandés.
Formez-vous gratuitement avec Alphorm !
Maîtrisez les compétences clés en IT grâce à nos formations gratuites et accélérez votre carrière dès aujourd'hui. Découvrez des cours variés pour tous les niveaux !

Conclusion
En maîtrisant SQL Python, vous combinez la flexibilité de Python avec la puissance des bases de données SQL. Cela vous permet de manipuler, automatiser et gérer efficacement les données. Que ce soit pour des requêtes simples ou complexes, SQL Python est un atout essentiel pour optimiser vos projets data.