La gestion des charges croissantes pose un défi majeur pour les systèmes informatiques.
Sans une bonne scalabilité, les systèmes risquent de ralentir ou de tomber en panne, impactant la performance et l’expérience utilisateur.
Cet article explore comment la scalabilité et la disponibilité peuvent être optimisées, en examinant le rôle du théorème CAP et des stratégies comme la réplication.
Initiez-vous à la Blockchain et explorez ses principes fondamentaux.

Scalabilité et Disponibilité Système
La scalabilité c’est la capacité d’un système à gérer une charge croissante de manière efficace. Imaginez une application web populaire : elle doit pouvoir s’adapter automatiquement à l’augmentation du nombre d’utilisateurs et à la charge qu’ils imposent. Deux éléments clés dans la scalabilité sont la performance et la disponibilité . Si le système n’est pas suffisamment scalable, il peut ralentir, voire tomber en panne quand la charge augmente. La scalabilité est essentielle pour rester performant et accessible en toutes circonstances.
Optimiser la Disponibilité pour Scalabilité
La disponibilité c’est le pourcentage de temps pendant lequel le système est fonctionnel. Elle se mesure en temps d’indisponibilité ou downtime par an, par exemple :
- Une disponibilité de 90 % signifie qu’il y a plus d’un mois d’indisponibilité par an,
- Avec 99.9 %, on a moins de 9 heures d’indisponibilité annuelle,
-
Avec 99.999 %, on descend à environ 31 secondes par an.
On voit bien que chaque « 9 » supplémentaire a un impact majeur pour les utilisateurs.
Tolérance aux Pannes et Scalabilité
La tolérance aux pannes, c’est la capacité d’un système à continuer de fonctionner malgré des pannes. Par exemple, si un serveur tombe en panne, le système doit être conçu pour continuer de fonctionner. Des mécanismes doivent être mis en place pour anticiper les pannes et assurer la continuité du service. Un bon exemple de cela est la réplication des serveurs critiques, ce qui permet de répartir la charge et de minimiser les impacts en cas de panne.
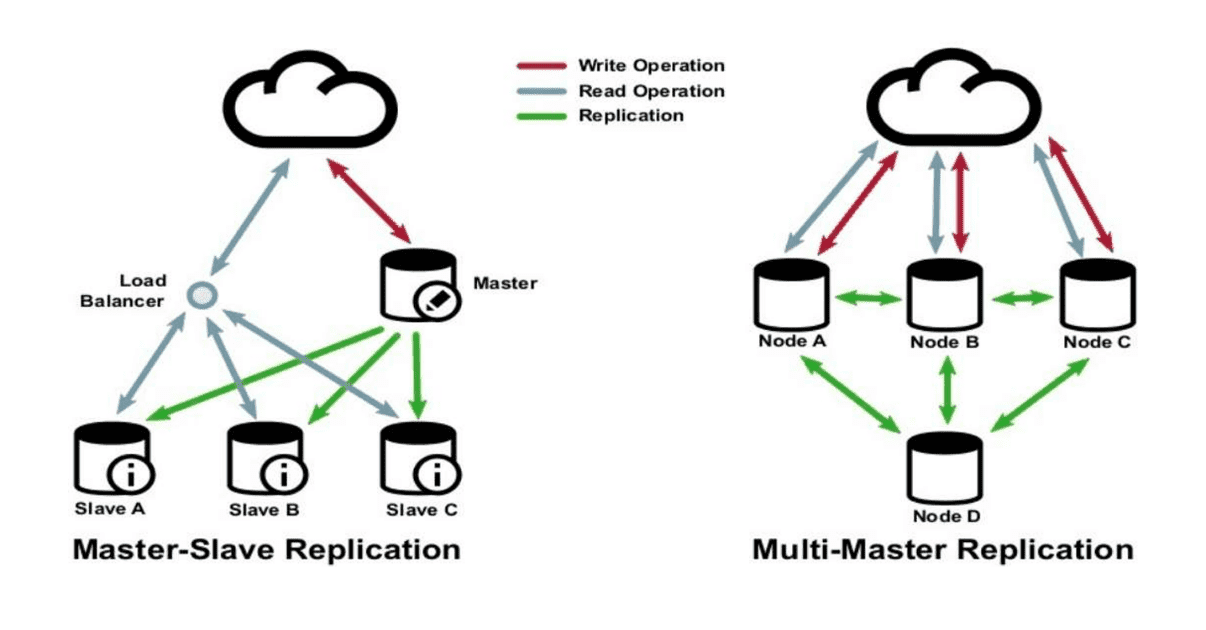
Réplication pour Meilleure Scalabilité
Quand on parle de réplication, on parle de faire des copies de données ou d’un nœud essentiel. Il y a deux types principaux de réplication :
- Réplication Master-Slave :Ici, on a un serveur principal (le master) qui contient les données originales, et plusieurs serveurs secondaires (slaves) qui reçoivent les mises à jour depuis le master. Par exemple, dans une base de données, le master synchronise ses données avec les slaves pour garantir que les informations sont disponibles même en cas de panne. Attention à la désynchronisation des données, qui reste un risque.
- Réplication Multi-Master :Dans ce modèle, tous les nœuds sont « maîtres » et se synchronisent entre eux. C’est une solution plus flexible mais qui complexifie la gestion de la cohérence des données.
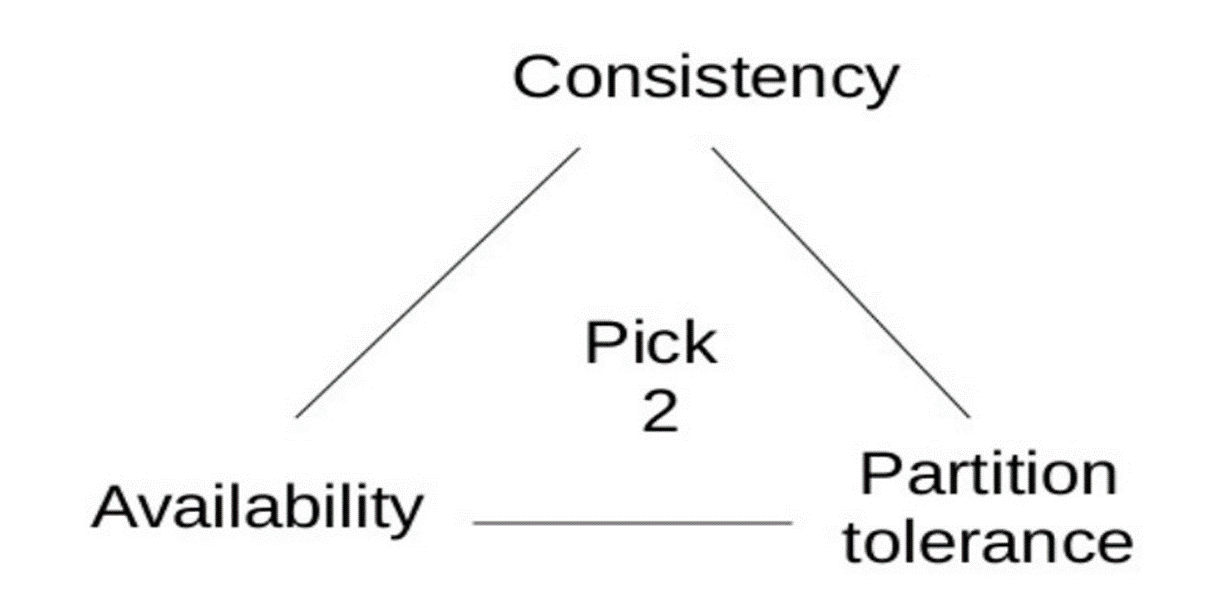
Théorème CAP et Scalabilité Systèmes
Ce théorème est central dans la théorie des systèmes distribués. il stipule qu’il est impossible de garantir en même temps les trois propriétés suivantes dans un système distribué :
- Cohérence :Tous les nœuds doivent toujours avoir les mêmes données au même moment.
- Disponibilité :Toutes les requêtes doivent recevoir une réponse, même si ce n’est pas la réponse la plus récente.
- Tolérance au Partitionnement :Le système doit continuer de fonctionner même en cas de coupure de certaines connexions réseau.
Selon le théorème CAP, on ne peut en garantir que deux sur trois à la fois dans un système distribué, et il faut donc faire des choix stratégiques selon les besoins.
Formez-vous gratuitement avec Alphorm !
Maîtrisez les compétences clés en IT grâce à nos formations gratuites et accélérez votre carrière dès aujourd'hui.

FAQ
Pourquoi la scalabilité est-elle importante pour les systèmes?
Qu'est-ce que la disponibilité d'un système?
Comment la tolérance aux pannes améliore-t-elle un système?
Quels sont les types de réplication existants?
Que stipule le théorème CAP dans les systèmes distribués?
Conclusion
En comprenant les concepts de scalabilité, disponibilité et tolérance aux pannes, comment pourriez-vous appliquer ces principes pour améliorer l’efficacité de vos systèmes informatiques?