Les développeurs rencontrent souvent des challenges dans l’ingestion et le traitement des données pour l’analyse en temps réel.
Ces difficultés peuvent entraîner des pertes de données critiques et des analyses inexactes, nuisant à la prise de décision.
Découvrez comment un pipeline Logstash bien configuré peut transformer vos flux de données, garantissant une intégration fluide avec Elasticsearch.
Devenez expert dans l'utilisation d'Elastic pour analyser les données !

Qu'est-ce qu'un pipeline Logstash ?
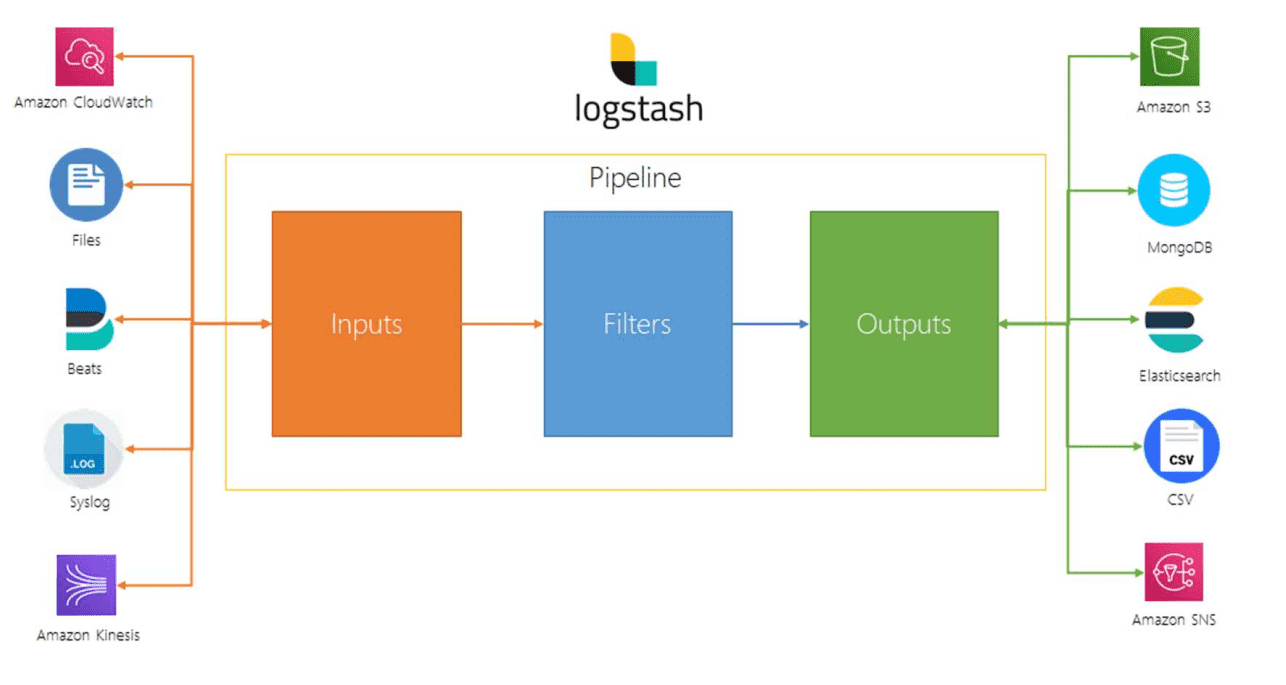
Logstash est un outil puissant de l’Elastic Stack utilisé pour l’ingestion, la transformation et l’acheminement des données depuis différentes sources vers différentes destinations (comme Elasticsearch). Il joue un rôle clé dans le traitement des logs et des données en temps réel.
Plugins Logstash pour l'ingestion de données
Logstash dispose de nombreux plugins pour les entrées (input), les filtres (filter), et les sorties (output), ce qui permet de connecter et de traiter les données provenant de différentes sources. Ces plugins sont configurés dans un pipeline.
Input | Filters | Output |
|---|---|---|
Amqp / Zeromq | CSV | Elasticsearch |
Eventlog (Windows) | JSON | Ganglia |
Ganglia | Grok | Graphite |
Zenoss | XML | Nagios |
log4j | Syslog_pri | OpenTSDB |
Syslog | Multiline | MongoDB |
TCP/UDP | Split | Zabbix |
(…) | (…) | (…) |
Ce tableau présente les différentes combinaisons possibles de sources d’entrée ( Input ), de filtres ( Filters ), et de systèmes de sortie ( Output ) dans un pipeline de traitement des données. Il montre comment des données provenant de systèmes variés, comme Amqp ou Windows Eventlog , peuvent être transformées à l’aide de filtres comme CSV ou JSON , puis envoyées vers des destinations comme Elasticsearch , MongoDB , ou Nagios .
Configurer un pipeline Logstash efficace
Un pipeline Logstash est constitué de trois sections principales : input , filter , et output . Voici un exemple de pipeline décomposé en étapes pour mieux comprendre son fonctionnement :
Exemple de Pipeline :
# Input Section: Reading logs from a file
input {
file {
path => "/home/student/03-grok-examples/sample.log"
start_position => "beginning" # Start reading from the beginning of the file
sincedb_path => "/dev/null" # Disable the sincedb file for file tracking
}
}
- input { file { … } } :Cette section permet de définir la source des données que Logstash va traiter. Ici, la source est un fichier de logs.
- path => « /home/student/03-grok-examples/sample.log » :Indique le chemin du fichier de logs à analyser. Logstash lira ce fichier pour en extraire les données.
- start_position => « beginning » :Indique à Logstash de commencer à lire le fichier depuis le début, même si des données ont déjà été collectées précédemment.
- sincedb_path => « /dev/null » :Cette option désactive le suivi de la position de lecture dans le fichier, généralement utilisé pour se souvenir de l’endroit où la lecture s’était arrêtée lors de la dernière exécution. En réglant cette valeur à /dev/null, Logstash recommence toujours à zéro à chaque exécution.
# Filter Section: Parsing logs with Grok
filter {
grok {
match => {
"message" => '%{TIMESTAMP_ISO8601:time} %{LOGLEVEL:logLevel} %{GREEDYDATA:logMessage}'
}
}
}
- filter { … } :Cette section traite les données extraites. Elle est utilisée pour transformer ou enrichir les données avant qu’elles ne soient envoyées à la sortie.
- grok { … } :Le pluginGrokest utilisé ici pour extraire des informations spécifiques à partir de chaque ligne de log en utilisant des expressions régulières.
- match =>{« message »=> ‘%{TIMESTAMP_ISO8601} %{LOGLEVEL} % {GREEDYDATA}’} :
- message fait référence au champ contenant les données de log brutes.
- TIMESTAMP_ISO8601 :Capture un horodatage ISO 8601 et l’associe au champtime.
- LOGLEVEL :Capture le niveau de log (ex. ERROR, INFO) et l’associe au champlogLevel.
- GREEDYDATA :Capture le reste de la ligne et l’associe au champlogMessage. Cela permet d’extraire l’ensemble du message de log.
Cette étape est cruciale pour structurer les logs non structurés, ce qui permet une analyse plus approfondie dans Elasticsearch.
# Output Section: Sending logs to Elasticsearch and stdout
output {
elasticsearch {
hosts => "http://localhost:9200" # Elasticsearch endpoint
index => "demo-grok" # Target index for log data
}
stdout { } # Outputting data to the console
}
}
- output { … } :Cette section spécifie où les données traitées par Logstash doivent être envoyées.
- elasticsearch { … } :Le pluginElasticsearchenvoie les données à un cluster Elasticsearch.
- hosts => « http ://localhost:9200″: Indique que les logs sont envoyés à un nœud Elasticsearch en local (sur la machine où Logstash s’exécute).
- index => « demo-grok » :Définit le nom de l’index où les logs seront stockés dans Elasticsearch. Ici, les logs sont envoyés dans un index nommédemo-grok.
- stdout { } :Cette directive affiche les logs traités directement dans la console, ce qui est utile pour le débogage.
Structure générale du pipeline Logstash
Le pipeline Logstash est organisé en trois étapes principales :
- Input :Collecte des données à partir d’une source (ici, un fichier de logs).
- Filter :Transformation et enrichissement des données, avec l’extraction d’informations spécifiques grâce à des plugins commeGrok.
- Output :Envoi des données transformées vers une destination (Elasticsearch et la console dans cet exemple).
# Input Section: Reading logs from a file
input {
file {
path => "/home/student/03-grok-examples/sample.log"
start_position => "beginning" # Start reading from the beginning of the file
sincedb_path => "/dev/null" # Disable the sincedb file for file tracking
}
}
# Filter Section: Parsing logs with Grok
filter {
grok {
match => {
"message" => '%{TIMESTAMP_ISO8601:time} %{LOGLEVEL:logLevel} %{GREEDYDATA:logMessage}'
}
}
}
# Output Section: Sending logs to Elasticsearch and stdout
output {
elasticsearch {
hosts => "http://localhost:9200" # Elasticsearch endpoint
index => "demo-grok" # Target index for log data
}
stdout { } # Outputting data to the console
}
Ce pipeline permet de structurer des données de logs non structurées en plusieurs champs bien définis, facilitant leur indexation et leur analyse dans Elasticsearch.
Formez-vous gratuitement avec Alphorm !
Maîtrisez les compétences clés en IT grâce à nos formations gratuites et accélérez votre carrière dès aujourd'hui.

FAQ
Comment fonctionne un pipeline Logstash?
Quels sont les plugins Logstash disponibles?
Comment configurer une section input dans Logstash?
Quelle est l'importance de la section filter dans Logstash?
Comment envoyer des données traitées à Elasticsearch avec Logstash?
Conclusion
En maîtrisant les pipelines Logstash, vous optimisez le traitement des données pour des analyses approfondies dans Elasticsearch. Comment envisagez-vous d’exploiter ces capacités dans vos projets futurs?