La manipulation précise des données SQL est cruciale en PL/SQL.
Sans un contrôle adéquat, les résultats peuvent être mal gérés, entraînant des erreurs ou des inefficacités.
Cet article explore les curseurs en PL/SQL, un outil essentiel pour accéder et traiter les données efficacement.
Maîtriser le langage SQL en environnement SGBDR. SQL n'aura plus de secrets pour vous !

Dans cette section, vous allez découvrir les concepts fondamentaux des curseurs en PL/SQL. Vous apprendrez à comprendre le rôle essentiel d’un curseur dans le traitement des données, ainsi qu’à identifier les différents types de curseurs disponibles et leurs applications respectives. Enfin, vous serez en mesure d’utiliser un curseur pour accéder à des données et les manipuler efficacement dans vos programmes PL/SQL.
Un curseur est un mécanisme essentiel qui permet de manipuler les résultats d’une requête SQL ligne par ligne, offrant ainsi un contrôle précis sur le traitement des données en PL/SQL. Il facilite l’accès aux données en permettant aux développeurs de travailler avec des ensembles de résultats de manière séquentielle.
Caractéristiques des curseurs
- Manipulation des données :Les curseurs permettent d’accéder à chaque ligne individuellement, ce qui est crucial pour les traitements nécessitant des modifications ou des analyses de données ligne par ligne.
- Contrôle du flux :Ils offrent une capacité de contrôle sur le flux des traitements PL/SQL en accédant aux informations de manière séquentielle, ce qui permet de gérer efficacement les transactions.
Fonctionnement des curseurs PL/SQL
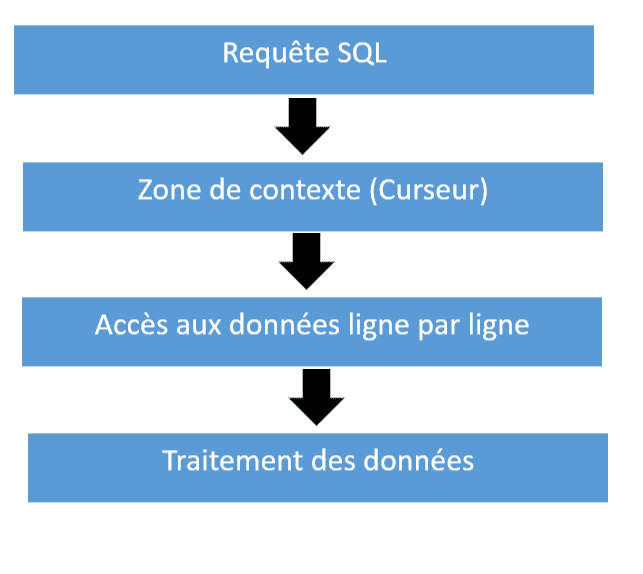
Le curseur crée une zone de contexte où la commande SQL est exécutée et les informations sont stockées. Ce contexte peut ensuite être nommé et manipulé pour :
- Accéder aux données de la requête ligne par ligne.
- Contrôler le traitement des données en PL/SQL.
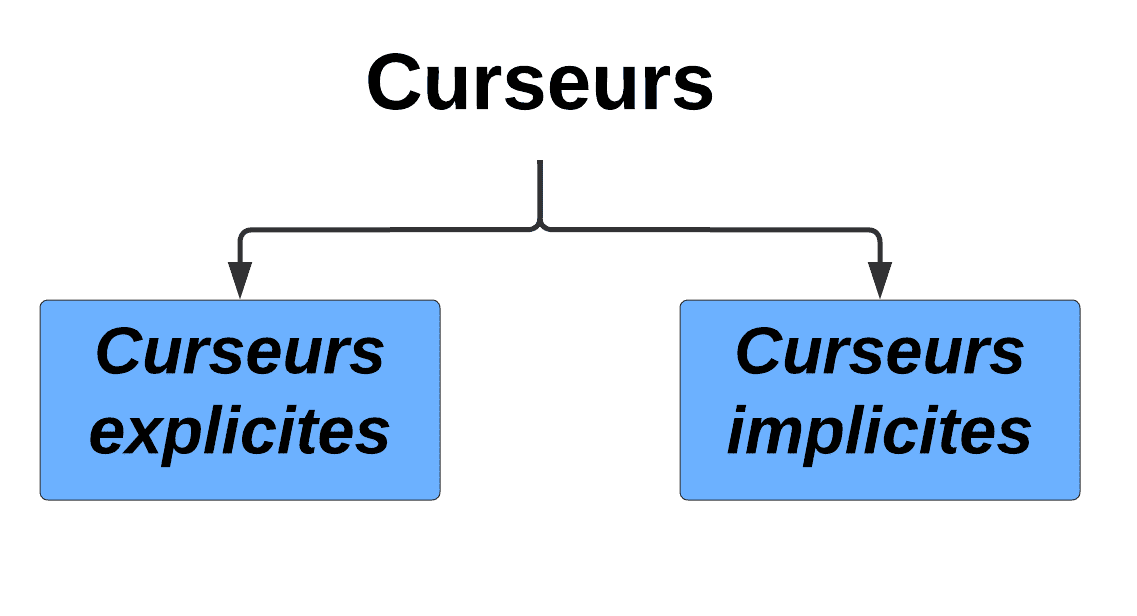
Types de curseurs : explicites et implicites
Il existe deux types principaux de curseurs en PL/SQL :
Curseurs explicites
- Utilisés pour traiter des requêtes qui renvoient plusieurs lignes.
- Nécessitent une déclaration et une gestion explicite (ouvrir, récupérer, et fermer).
Curseurs implicites
- Gérés automatiquement par PL/SQL pour les commandes SQL qui renvoient une seule ligne.
- Inutile de les déclarer ou de les fermer manuellement.
Utilisation des curseurs pour la manipulation des données
Un curseur en PL/SQL suit un cycle de vie structuré, composé de quatre étapes essentielles : Déclaration, Ouverture, Défilement des données et Fermeture. Chacune de ces étapes joue un rôle crucial dans la gestion des données au sein d’une base de données.
Déclaration (DECLARE)
La première étape consiste à déclarer le curseur . Cette déclaration définit la requête SQL qui sera exécutée et prépare le curseur pour son ouverture. À cette étape, vous spécifiez également les types de données que vous allez manipuler.
Importance de la déclaration :
- Elle établit les conditions et les critères de la requête, permettant ainsi de définir quelles données seront extraites.
- Cela permet également de gérer la structure des données à récupérer, en précisant les types de données dans les variables associées.
Ouverture (OPEN)
La deuxième étape, l’ouverture , implique l’exécution de la requête SQL définie lors de la déclaration. À ce stade, un contexte de curseur est créé, et les données résultant de la requête sont chargées dans ce contexte.
Fonctionnalités de l’ouverture :
- Lorsqu’un curseur est ouvert, il prépare la zone de mémoire pour stocker les résultats de la requête, permettant un accès direct aux lignes.
- Il est essentiel d’ouvrir le curseur avant d’essayer d’extraire des données ; sinon, une erreur sera générée.
Défilement des données (FETCH)
Une fois le curseur ouvert, vous pouvez commencer à défiler les données . Cette étape consiste à récupérer les lignes de résultats une par une pour les traiter individuellement.
Rôle du défilement :
- Permet d’extraire les résultats de la requête ligne par ligne, ce qui est utile pour le traitement séquentiel des données.
- Vous pouvez appliquer des conditions et des traitements spécifiques à chaque ligne extraite, offrant ainsi une flexibilité dans la manipulation des données.
Fermeture (CLOSE)
Enfin, la dernière étape est la fermeture du curseur. Après que toutes les données ont été traitées, il est crucial de fermer le curseur pour libérer les ressources qu’il utilise.
Importance de la fermeture :
- Fermer un curseur permet de libérer la mémoire et les ressources associées à ce curseur, évitant ainsi les fuites de mémoire et garantissant la performance de l’application.
- Cela indique également que vous avez terminé de travailler avec les résultats du curseur, permettant à d’autres opérations de base de données de s’exécuter sans conflit.
Formez-vous gratuitement avec Alphorm !
Maîtrisez les compétences clés en IT grâce à nos formations gratuites et accélérez votre carrière dès aujourd'hui.

FAQ
Comment fonctionne un curseur en PL/SQL ?
Quels sont les types de curseurs en PL/SQL ?
Pourquoi est-il important de fermer un curseur ?
Comment déclarer un curseur en PL/SQL ?
Quelle est la différence entre l'ouverture et le défilement d'un curseur ?
Conclusion
En maîtrisant les concepts des curseurs PL/SQL, vous optimisez votre gestion des données. Comment pourriez-vous appliquer ces techniques pour améliorer vos processus de traitement de données en PL/SQL ?