La gestion et l’optimisation des données deviennent complexes avec l’augmentation des volumes d’information.
Sans une architecture adaptée, la recherche et l’analyse des données peuvent devenir inefficaces et coûteuses.
Cet article explore divers modes de déploiement, comme le standalone et le clustering, pour améliorer l’indexation et la recherche.
Maîtrisez les fonctionnalités de base dans l'analyse de logs avec Splunk

Déploiement Standalone et Indexation
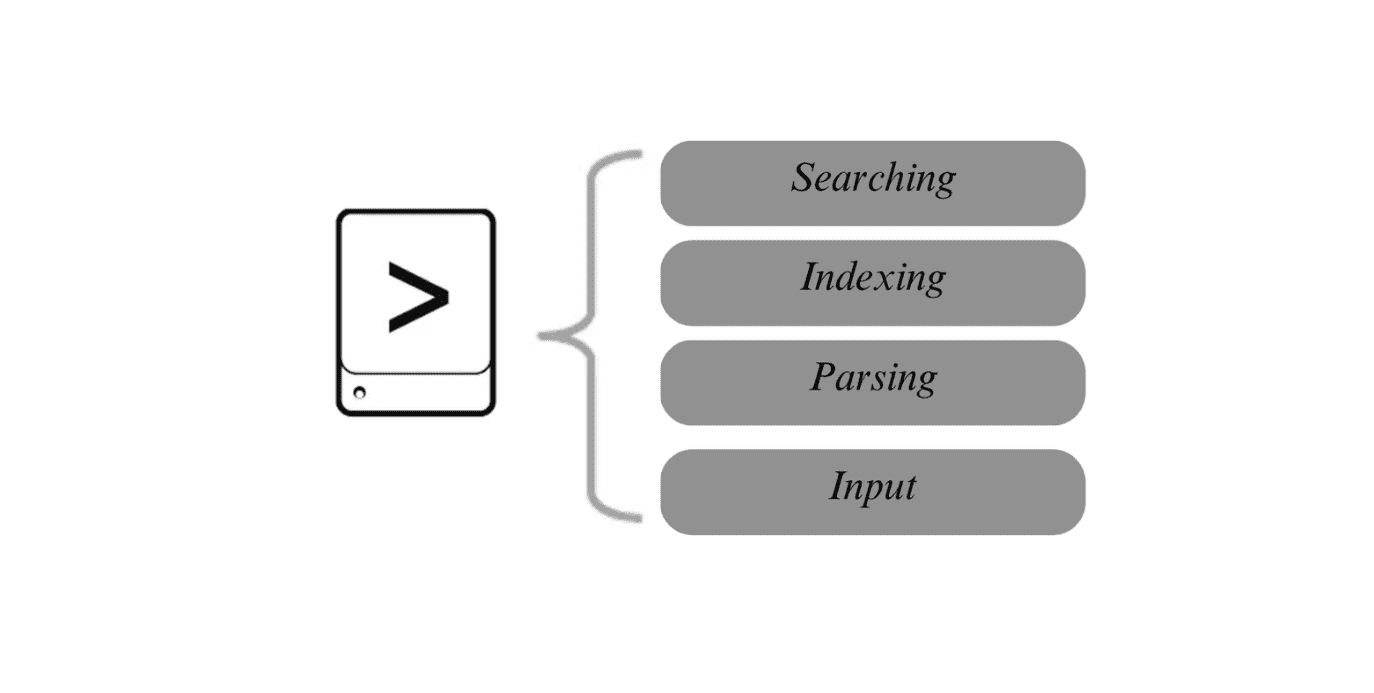
- Input :Cette étape consiste à recevoir les données d’entrée, qui peuvent provenir de diverses sources telles que des utilisateurs, des fichiers ou d’autres systèmes. Dans le contexte d’un moteur de recherche en mode standalone, les données d’entrée peuvent être des documents texte que le système va analyser et indexer.
- Parsing :Le parsing est le processus d’analyse des données d’entrée pour en extraire des informations exploitables. Par exemple, dans un moteur de recherche, le système analyse le contenu des documents pour extraire des mots-clés et d’autres informations structurées nécessaires pour l’indexation.
- Indexing :L’étape d’indexation consiste à organiser les données extraites afin qu’elles puissent être rapidement consultées lors de la recherche. Dans le cas d’un moteur de recherche, cela implique de construire une structure d’index qui associe chaque mot-clé à son emplacement dans les documents analysés, facilitant ainsi la recherche rapide.
- Searching :La recherche est l’étape où le système interroge l’index pour retrouver des informations spécifiques en fonction de critères donnés par l’utilisateur. Dans un moteur de recherche en mode standalone, cette étape implique de scanner l’index pour trouver les documents correspondant aux mots-clés recherchés.
Déploiement avec Forwarders Efficaces
Le déploiement basique introduit des agents appelés forwarders , qui collectent des logs et les transmettent à un serveur central pour analyse.
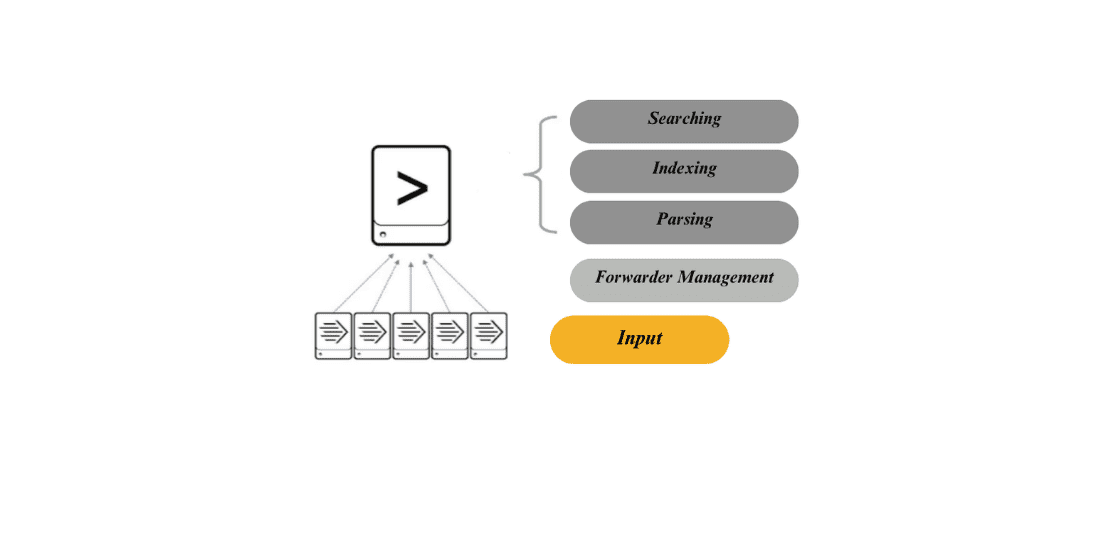
- Input :Les « forwarders » collectent les données d’entrée (logs) depuis diverses sources et les envoient au serveur central. Par exemple, chaque serveur d’une entreprise peut envoyer ses logs système à un forwarder, qui les regroupe pour analyse.
- Forwarder Management :Cette étape consiste à gérer et surveiller les agents « forwarders » pour s’assurer qu’ils fonctionnent correctement et transmettent bien les données au serveur central.
- Parsing :Une fois les logs reçus, le système analyse les données pour extraire des informations importantes, comme des erreurs ou des événements spécifiques.
- Indexing :Les données extraites sont indexées pour permettre des recherches rapides. Par exemple, les erreurs fréquentes sont organisées pour qu’elles soient facilement repérables.
- Searching :Le serveur central utilise l’index pour effectuer des recherches sur les logs collectés. L’utilisateur peut alors interroger le système pour trouver des informations spécifiques, comme les logs d’une machine particulière.
- Mode de Déploiement Multi-Instances
Le mode multi-instances repose sur une architecture en clustering , où plusieurs serveurs travaillent ensemble pour améliorer l’indexation et la recherche.
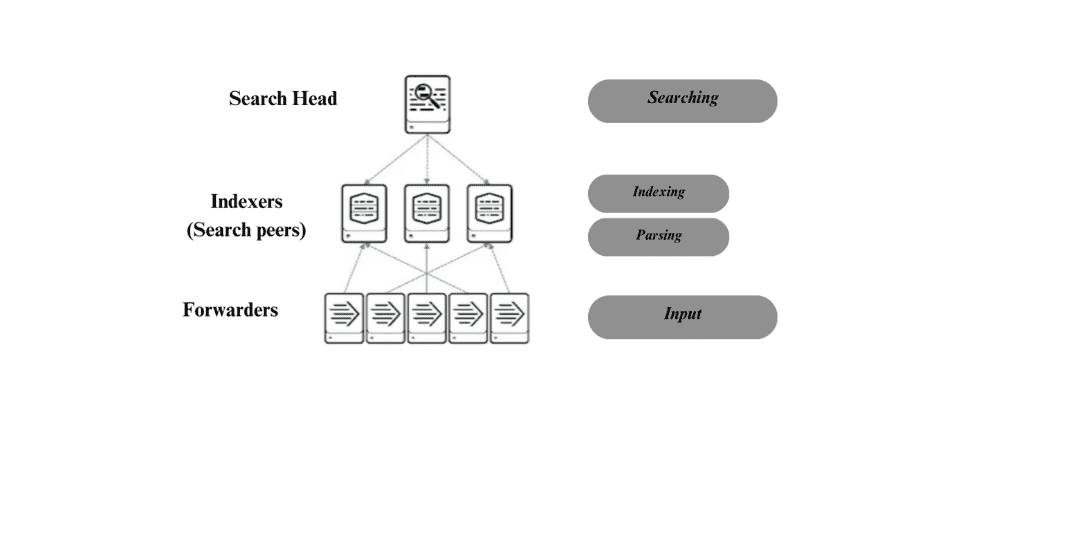
- Entrée (Input) :
Les Forwarders collectent les données brutes (comme les journaux système) de diverses sources et les envoient aux Indexers .
- Analyse syntaxique (Parsing) :
Les données brutes sont transformées en événements individuels, où des champs clés (comme les adresses IP ou les utilisateurs) sont extraits pour faciliter l’analyse.
- Indexation (Indexing) :
Les Indexers stockent et organisent ces événements dans un index, ce qui permet d’accélérer la recherche des informations nécessaires.
- Recherche (Searching) :
Le Search Head permet aux utilisateurs de rechercher et d’analyser les données indexées, en générant des rapports et des tableaux de bord pour la visualisation.
- Déploiement avec Capacités Croissantes
Ce mode se concentre sur la capacité d’augmenter les ressources de manière dynamique en fonction des besoins croissants.

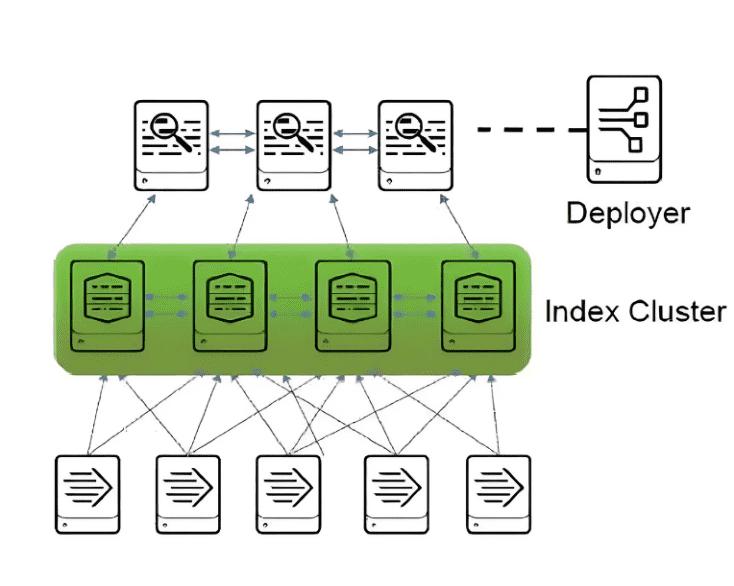
- Search Head Cluster (Cluster de Têtes de Recherche) :
Ce cluster est composé de plusieurs instances de Search Heads qui travaillent ensemble pour permettre des recherches parallèles et une gestion partagée des requêtes. Cette architecture améliore la performance des recherches et offre une haute disponibilité en répartissant la charge de travail entre plusieurs têtes de recherche.
- Indexers (Indexeurs) :
Les indexeurs stockent et organisent les données reçues des forwarders pour qu’elles soient rapidement disponibles pour la recherche. Ils reçoivent les requêtes des Search Heads et renvoient les résultats de recherche pertinents. Dans un déploiement à capacité croissante, plusieurs indexeurs sont ajoutés pour gérer de plus gros volumes de données sans compromettre la rapidité.
- Forwarders (Transmetteurs) :
Les forwarders collectent les données des différentes sources et les transmettent aux indexeurs. Dans une architecture avec des capacités croissantes, de nouveaux forwarders peuvent être ajoutés pour couvrir davantage de sources de données à mesure que les besoins augmentent.
- Deployer :
Le déployer est un composant responsable de la configuration et de la gestion centralisées des instances du cluster de têtes de recherche. Il simplifie la gestion de la configuration lorsque de nouveaux Search Heads sont ajoutés, permettant ainsi une évolutivité plus fluide.
- Clusters d’Indexation
Les clusters d’indexation se divisent en deux catégories principales : les clusters non répliquants et les clusters répliquant.
- Clusters non répliquants :
-Simplicité : Faciles à configurer, mais manquent de mécanismes de récupération des données. En cas de défaillance, les données peuvent être perdues.
- Clusters répliquants :
-Disponibilité et sécurité : Répliquent les données sur plusieurs serveurs, ce qui garantit une haute disponibilité et prévient la perte de données.
-Gestion complexe : Bien que plus robustes, ils nécessitent une gestion plus sophistiquée en raison de la duplication des données.
Formez-vous gratuitement avec Alphorm !
Maîtrisez les compétences clés en IT grâce à nos formations gratuites et accélérez votre carrière dès aujourd'hui.

FAQ
Qu'est-ce que le mode de déploiement standalone?
Comment fonctionnent les forwarders dans un déploiement basique?
Qu'est-ce que le clustering dans un mode multi-instances?
Comment le Search Head Cluster améliore-t-il la recherche?
Quels sont les avantages des clusters répliquants?
Conclusion
En conclusion, différents modes de déploiement offrent des solutions uniques pour la gestion des données. Quel mode de déploiement pensez-vous pourrait le mieux répondre à vos besoins spécifiques en matière de gestion des données?