La gestion des configurations d’infrastructure peut devenir complexe et difficile à maintenir.
Cela entraîne des erreurs fréquentes, une duplication des tâches et une perte de temps considérable.
Les rôles Ansible offrent une structure claire et réutilisable pour simplifier et améliorer l’efficacité de la gestion des configurations.
Devenez un expert d'Ansible et simplifiez vos tâches d'administration.

Qu'est-ce qu'un rôle Ansible ?
Dans ce chapitre, nous allons apprendre ensemble les rôles. Ce sont des regroupements structurés de tâches qui forment des composants réutilisables. Ils permettent de regrouper et d’ordonner des actions, de gérer des templates pour les inventaires, et d’attribuer des variables de manière organisée.
Structure des rôles Ansible
Un rôle est la subdivision structurée des diverses sections d’un playbook. Chaque partie est organisée de manière spécifique à travers un ensemble de répertoires et de fichiers.
La structure des rôles en Ansible est généralement organisée comme suit :
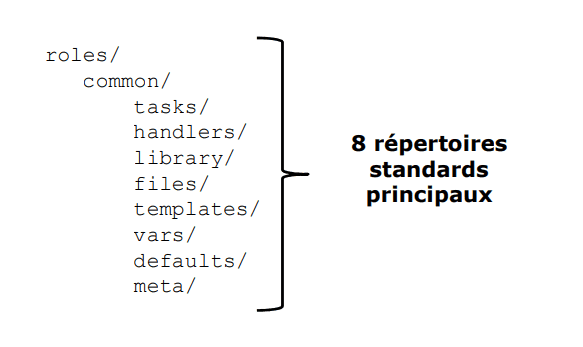
tasks / : Contient les fichiers YAML décrivant les tâches à exécuter.
handlers / : Contient les gestionnaires d’événements (handlers) appelés par les tâches lorsqu’un changement est nécessaire.
library / : Optionnel. Contient les modules personnalisés utilisés par le rôle.
files / : Optionnel. Contient les fichiers statiques à copier sur les hôtes gérés.
templates / : Contient les fichiers de templates Jinja2 qui peuvent être utilisés pour générer des configurations sur les hôtes gérés.
vars / : Contient les variables spécifiques au rôle qui peuvent être utilisées dans les tâches et les templates.
defaults / : Contient les valeurs par défaut des variables utilisées dans le rôle, qui peuvent être surchargées par l’utilisateur.
meta / : Contient les informations métadonnées sur le rôle, telles que les dépendances avec d’autres rôles.
Cette structure permet de séparer clairement les différentes parties fonctionnelles d’un rôle Ansible, facilitant ainsi la réutilisation, la gestion et la maintenance des configurations d’infrastructure.
Stockage des rôles avec roles_path
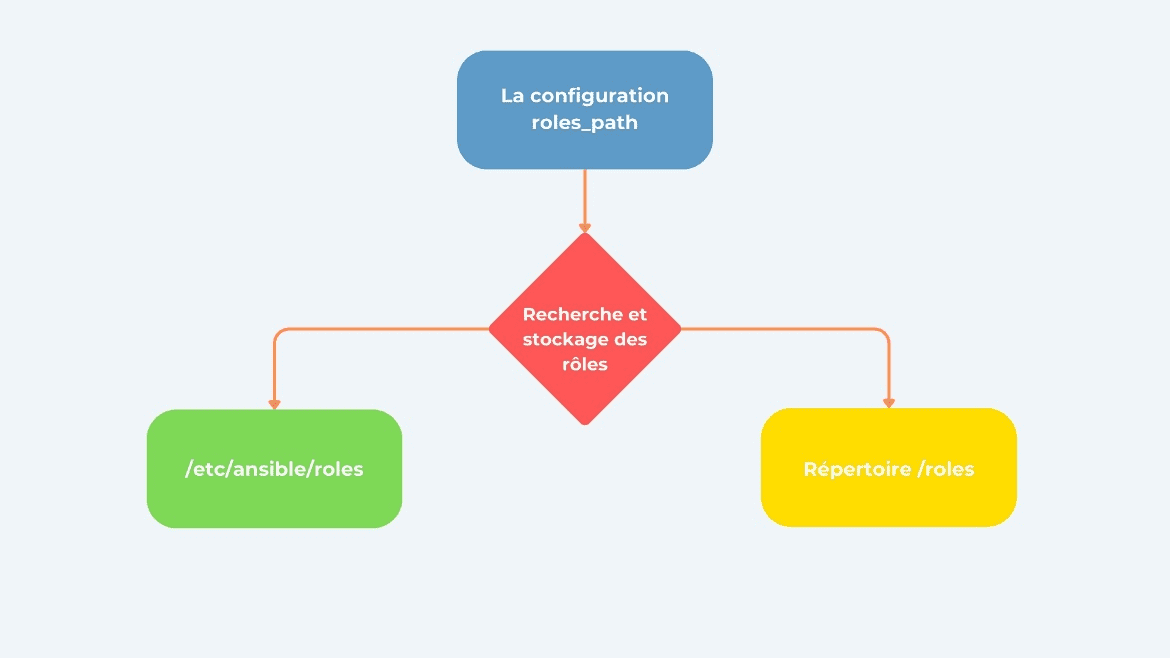
Le stockage et la recherche des rôles en Ansible se font principalement à travers le paramétrage des chemins (roles_path). Voici comment cela fonctionne :
Recherche des rôles : Ansible recherche les rôles dans les répertoires spécifiés par roles_path. Par défaut, Ansible recherche dans le répertoire roles / à partir du répertoire où nous exécutons Ansible (./ roles /). Nous pouvons également spécifier d’autres répertoires où Ansible devrait rechercher les rôles en configurant roles_path dans le fichier de configuration Ansible (ansible.cfg).
Stockage des rôles : Nous pouvons stocker nos rôles dans les répertoires spécifiés par roles_path . Typiquement, les rôles sont organisés sous forme de sous-répertoires nommés par le nom du rôle (par exemple, roles/<nom_du_role>/). À l’intérieur de ces répertoires, nous retrouverons la structure standard des rôles d’Ansible (tasks, handlers, vars, etc.) pour chaque rôle.
Par exemple, si nous avons un rôle nommé common , nous pourrions l’organiser ainsi :
roles/
common/
tasks/
handlers/
...
Lorsque nous spécifions roles_path dans notre configuration Ansible, cela indique à Ansible où chercher ces rôles lors de l’exécution des playbooks. Cela facilite la réutilisation et la gestion centralisée des rôles dans vos environnements Ansible.
Voici un visuel récapitulatif de la recherche et stockage des rôles :
Utilisation efficace des rôles Ansible
Utilisation classique et statique dans une pièce (playbook) : Avant l’introduction des directives import_role et include_role, les rôles étaient principalement utilisés de manière statique dans les playbooks. Voici un exemple de cette ancienne méthode :
---
- hosts: webservers
roles:
- common
- web
Dans cet exemple, les rôles common et web sont directement inclus dans le playbook. Cette méthode est simple et efficace pour les scénarios où les rôles sont toujours nécessaires et exécutés dans un ordre fixe.
Nouvelle Utilisation des Rôles : Avec l’introduction des directives import_role et include_role, Ansible offre désormais plus de flexibilité et de dynamisme dans la gestion des rôles. Ces directives permettent d’importer ou d’inclure des rôles de manière conditionnelle et dynamique.
- Import Rôle :La directiveimport_roleest utilisée pour importer des rôles statiquement au moment du traitement du playbook. L’importation se fait avant l’exécution du playbook, ce qui signifie que les tâches du rôle sont chargées comme si elles faisaient partie du playbook d’origine.
---
- hosts: webservers
tasks:
- name: Import common role
import_role:
name: common
- name: Import web role
import_role:
name: web
- Include Role :La directive include_role est utilisée pour inclure des rôles dynamiquement au moment de l’exécution. Cela permet de conditionner l’inclusion des rôles en fonction des variables ou des résultats des tâches précédentes.
---
- hosts: webservers
tasks:
- name: Include common role
include_role:
name: common
- name: Conditionally include web role
include_role:
name: web
when: webserver_needed
La nouvelle méthode utilisant import_role et include_role offre une meilleure modularité et la possibilité de conditionner l’exécution des rôles, ce qui permet de créer des playbooks plus complexes et adaptatifs.
Critère | Include rôle | Import rôle |
|---|---|---|
Moment d’inclusion | Dynamique (au moment de l’exécution) | Statique (au moment de la lecture du playbook) |
Capacité à utiliser des variables dynamiques | Oui | Non |
Structure de code | Moins strict, car inclus dynamiquement | Plus strict, doit être connu à l’avance |
Performances | Moins performant (inclusion au moment de l’exécution) | Plus performant (préparé au moment de la lecture) |
Utilisation | Utilisé lorsque le rôle doit être conditionnel ou basé sur des variables dynamiques | Utilisé pour des rôles fixes et connus à l’avance |
Exécution d’un rôle de façon multiple dans Ansible : Ansible permet d’exécuter un rôle plusieurs fois dans un même playbook grâce à la directive allow_duplicates. Cela peut être utile lorsque nous souhaitons appliquer le même rôle avec des configurations ou des contextes différents.
Un exmple :
---
- hosts: webservers
roles:
- foo
- foo
# roles/foo/meta/main.yml
---
allow_duplicates: true
Dans cet exemple, le rôle foo est appelé deux fois. Par défaut, Ansible ne permet pas l’exécution multiple d’un même rôle dans un même playbook pour éviter les redondances non voulues. Pour contourner cette restriction, nous devons utiliser la directive allow_duplicates dans la méta-données du rôle.
L’objectif principal des dépendances de rôles est de garantir que certains rôles sont exécutés avant celui en cours, assurant ainsi que toutes les conditions préalables sont remplies. Cela permet d’automatiser le processus de préparation de l’environnement nécessaire pour chaque rôle.
Exécution pratique des rôles Ansible
Dans cette section, nous allons créer un nœud géré dans la console AWS. Voici nos trois nœuds dans la console, et nous avons nommé le troisième nœud que nous avons instancié » noeudGredhat » :

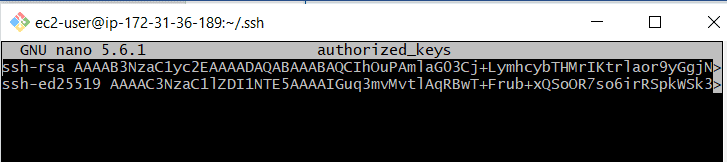
Maintenant nous avons mis en place nos trois nœuds, copions la clé publique du nœud de contrôle vers le troisième nœud ( noeudGredhat ) afin de pouvoir s’y connecter depuis le nœud de contrôle. Pour ce faire, accédez au dossier . ssh sur le nœud de contrôle et lisez le contenu de la clé publique id_ed25519.pub . Copier ensuite ce contenu dans le fichier authorized_keys de notre troisième nœud. Voici la clé publique du nœud de contrôle :

Copions cette clé dans le fichier authorized_keys du troisième nœud comme ceci :
Une fois la clé copiée, nous allons tester la connexion depuis le nœud de contrôle vers ce nœud en utilisant la commande suivante : ssh ec2-user@15.188.59.150 . Ici, ec2-user est le nom de l’utilisateur sur la machine cible (Troisième nœud ), et 15.188.59.150 est son adresse IP publique.
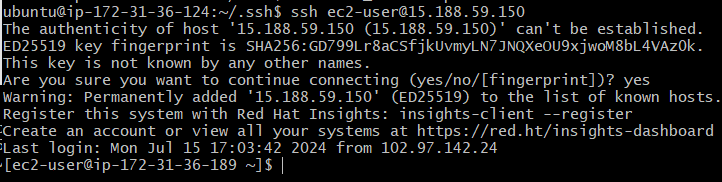
Bravo, connexion au troisième nœud par la connexion ssh est réussite. Nous pouvons clairement observer que le nom et l’adresse IP du terminal ont été remplacés par ceux du troisième nœud.
Parfait, ajoutons maintenant ce nœud dans l’inventaire du nœud de contrôle pour le manipuler avec ansible.
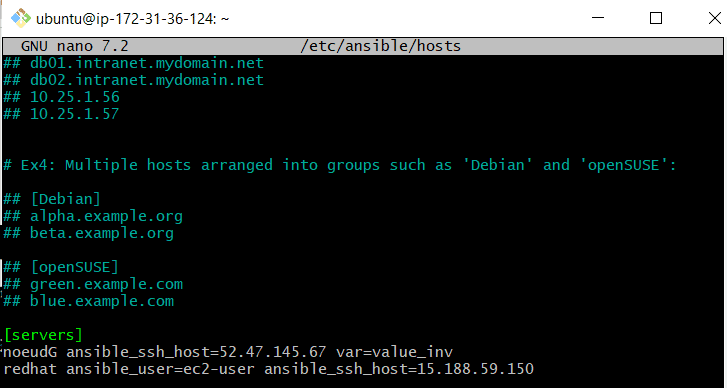
Très bien …………………. Nous avons maintenant ajouté le troisième nœud à notre inventaire, portant le total à deux nœuds à gérer. Nous avons spécifié ansible_user=ec2-user car l’utilisateur par défaut était ubuntu, ce qui est différent de notre nouveau système qui est Red Hat.
Passons désormais au vif du sujet de ce chapitre, nous allons créer un playbook pour installer et mettre à jour Apache sur nos nœuds gérés. Voici la structure des rôles que nous allons mettre en place pour cette tâche :

Le fichier roles-playbook.yml est utilisé pour définir les rôles des tâches, tandis que le dossier tasks contient les tâches d’installation et de configuration. Ensuite, le dossier vars contient les variables spécifiques à chaque système d’exploitation. Passons maintenant au développement des fichiers de tâches avec leur contenu respectif :
Pour tasks/main.yml
tasks/main.yml
---
- include_vars: "{{ansible_os_family}}.yml"
- import_tasks: install.yml
- import_tasks: configure.yml
- import_tasks: service.yml
Dans ce fichier, nous avons importé toutes fichier contenant les taches du playbook.
Pour le fichier tasks/install.yml
tasks/install.yml
---
- name: install package with yum
yum:
name: "{{package_name}}"
state: "{{package_version}}"
install.yml : c’est le fichier qui contient la tâche d’installation d’Apache sur une machine basée sur Red Hat.
Pour le fichier configuration, voici son contenu : tasks/configure.yml
---
- name: copy apache configuration file
copy:
src: "{{package_name}}.config"
dest: "{{config_dest_file}}"
Nous utilisons le module copy : Ceci est le module Ansible utilisé pour copier des fichiers depuis le contrôleur Ansible vers les hôtes cibles.
src: « {{package_name}}.config » : Cette ligne spécifie le chemin du fichier source à copier. Le nom du fichier source est construit dynamiquement en utilisant la variable {{package_name}} suivie de l’extension.config. La variable package_name doit être définie ailleurs dans les variables.
dest: « {{config_dest_file}} » : Cette ligne spécifie le chemin de destination où le fichier sera copié sur l’hôte cible. La variable {{config_dest_file}} doit également être définie ailleurs dans le playbook ou les variables.
Pour les services, voici le contenu di fichier : tasks/service.yml
---
- name: Enable apache
service:
name: "{{package_name}}"
enabled: yes
state: restarted
Cette tache redémarre juste apache dans les nœuds gérés.
Passons maintenant aux variables. Étant donné que nous avons deux systèmes d’exploitation différents sur nos nœuds gérés, nous allons développer deux jeux de variables pour chacun de ces systèmes. Voici le contenu des variables pour le nœud basé sur Debian (Ubuntu) : vars/Debian.yml
---
package_name: apache2
package_version: latest
config_dest_file: /etc/apache2/apache2.conf
package_name: apache2 : Cette variable définit le nom du package à installer. Dans ce cas, le package s’appelle apache2.
package_version: latest : Cette variable spécifie la version du package à installer. Ici, latest indique qu’Ansible doit installer la dernière version disponible du package apache2.
config_dest_file: /etc/apache2/apache2.conf : Cette variable spécifie le chemin du fichier de configuration d’Apache sur la machine cible.
Pour le nœud basé sur redhat : vars/RedHat.yml
---
package_name: httpd
package_version: latest
config_dest_file: /etc/httpd/httpd.conf
Cette variable fait la même chose comme la variable précédente mais juste pour le nœud basé sur redhat.
Maintenant, il nous reste le playbook, donc voici sontìcontenu : roles-playbook.yml
---
- hosts: servers
tasks:
- debug:
msg: "Before running role"
- include_role:
name: apache
- debug:
msg: "After running role"
Ce playbook exécute trois tâches sur les hôtes du groupe servers :
- Affiche un message avant l’exécution du rôle apache.
- Inclut et exécute le rôle apache.
- Affiche un message après l’exécution du rôle apache.
Tout est prêt et disponible. Créons les fichiers à l’endroit désigné et copions le contenu de chacun. À la fin de la création des dossiers et fichiers, nous devrions obtenir une structure comme celle-ci :
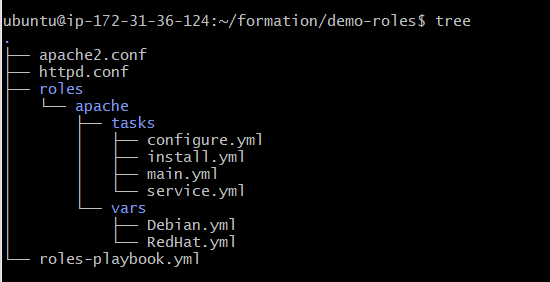
Super, nous avons bien mis en place la structure des rôles. Pour cette étape pour la copie des contenus et création des dossiers, commencez par créer le dossier ‘demo-roles’ avec la commande ‘ mkdir demo-roles’ . Ensuite, à l’intérieur de ce dossier, créez les fichiers ‘apache2.conf’ , ‘httpd.conf’ et ‘roles-playbook.yml’ avec la commande ‘nano nom-fichier’ . Ensuite, créez également le dossier ‘roles’ et à l’intérieur de celui-ci, créez le dossier ‘apache’ . Dans le dossier ‘apache’ , créez les dossiers ‘tasks’ et ‘vars’ , puis enfin, créez les fichiers respectifs dans ces dossiers. »
Executons maintenant notre playbook avec la commande : ansible-playbook -v roles-playbook.yml –become, et il nous affiche le résultat comme ceci :
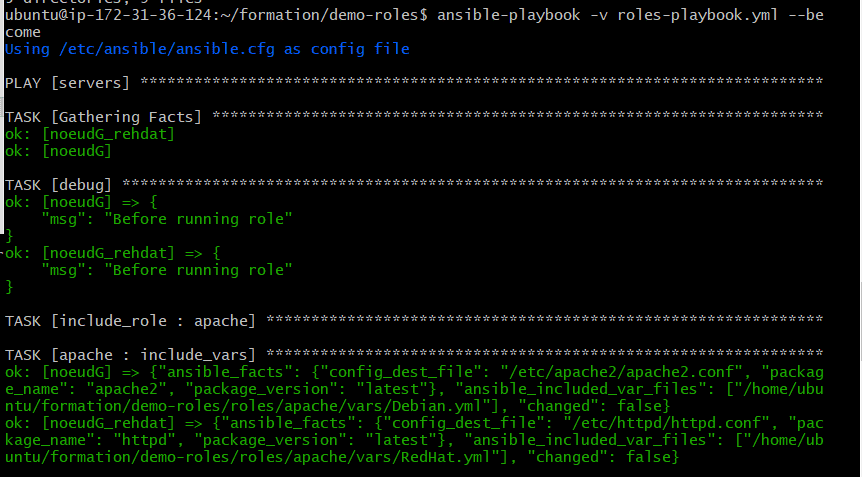
Parfait, nous obtenons le résultat attendu et nous pouvons aussi vérifier la version d’apache installer avec la commande : apache2 –version et cela nous affiche sa version
Voilà, nous avons terminé cette partie avec succès.
Utilisation des rôles
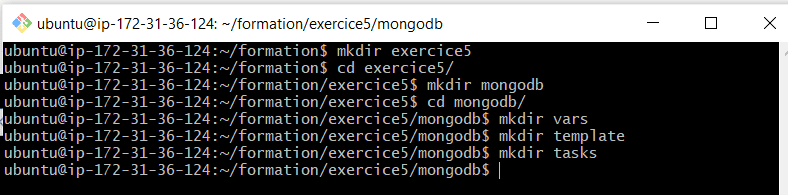
Dans ce dernier exercice, nous allons utiliser rôles pour créer un rôle mongodb avec l’arborescence suivante qui essaye d’installer, demarrer mongodb dans le nœud géré :
Mongodb :
Tasks 🡺 main.yml : pour les tâches à exécuter
Vars 🡺 main.yml: pour les variables relatives aux compte utilisateurs
Templates 🡺 mongo.conf.j2
Donc avant de traiter l’exercice, créons maintenant l’arborescence de notre dossier : Voila l’architecture de notre projet.
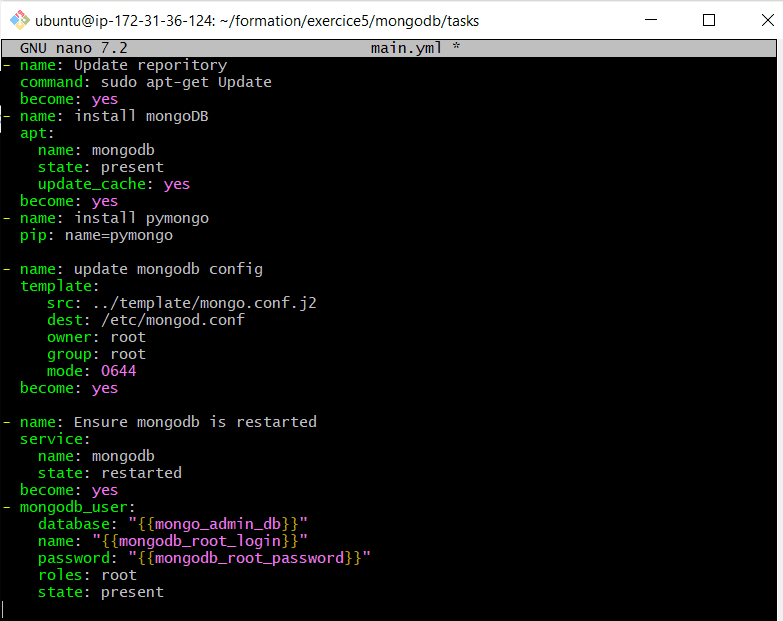
Ensuite, developper le contenu du fichier main.yml des tâches (tasks) : tasks/main. yml
– name: Update reporitory
command: sudo apt-get Update
become: yes
– name: install mongoDB
apt:
name: mongodb
state: present
update_cache: yes
become: yes
– name: install pymongo
pip: name=pymongo
– name: update mongodb config
template:
src: ../template/mongo.conf.j2
dest: /etc/mongod.conf
owner: root
group: root
mode: 0644
become: yes
– name: Ensure mongodb is restarted
service:
name: mongodb
state: restarted
become: yes
– mongodb_user:
database: « {{mongo_admin_db}} »
name: « {{mongodb_root_login}} »
password: « {{mongodb_root_password}} »
roles: root
state: present
Copions le dans le fichier tasks/main.yml pour pouvoir l’executer après.
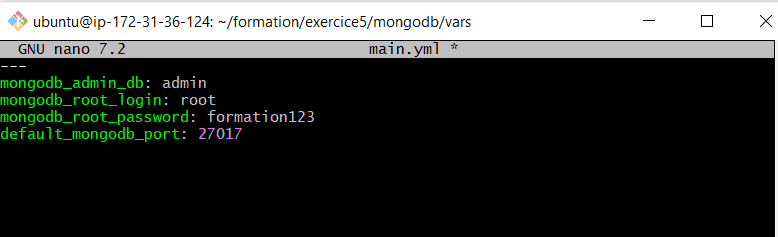
Le contenu du fichier main de vars : vars/main.yml qui contient juste les variables d’un compte.
—
mongodb_admin_db: admin
mongodb_root_login: root
mongodb_root_password: formation123
default_mongodb_port: 27017
Pour le template. Voici le contenu : template / mongo.conf.j2
storage:
dbPath: /var/lib/mongodb
journal:
enabled: true
systemLog:
destination: file
logAppend : true
path: /var/log/mongodb/mongo.log
net:
port: {{default_mongodb_port}}
setParameter:
enableLocalhostAuthBypass: false
Après avoir créé l’arborescence de l’exercice et copié le contenu de chaque fichier, voilà la structure de nos fichier et dossier. Nous pouvons l’afficher avec la commande : tree
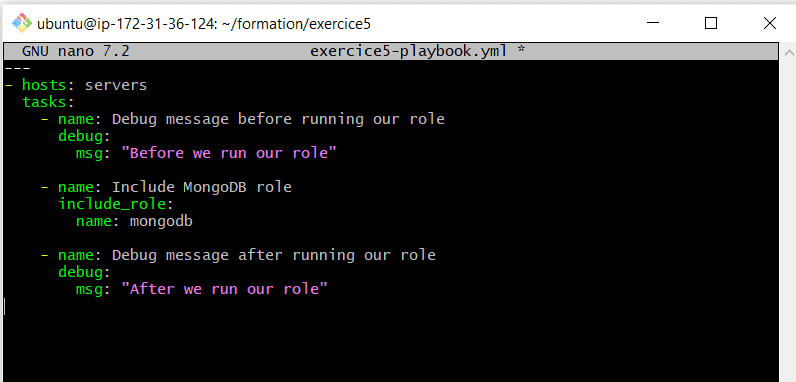
Maintenant, copions le contenu du playbook dans le fichier exercice5-playbook.yml comme ceci.
Tout est prêt à être exécuté. Positionnons-nous dans le dossier exercice5 et lançons la commande suivante pour exécuter le playbook : ansible-playbook -v exercice5-playbook.yml –become
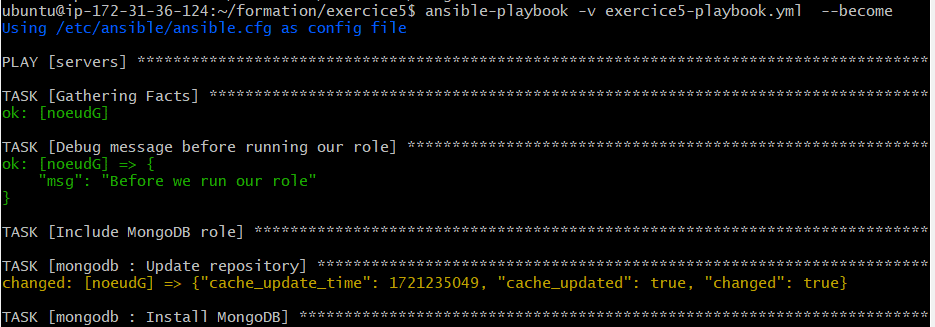
Parfait, comme indiqué sur le visuel, le playbook a été exécuté avec succès. Nous avons donc terminé cet exercice avec succès. Nous avons les connaissances nécessaires pour débuter avec Ansible maintenant.
Formez-vous gratuitement avec Alphorm !
Maîtrisez les compétences clés en IT grâce à nos formations gratuites et accélérez votre carrière dès aujourd'hui.

FAQ
Qu'est-ce qu'un rôle en Ansible?
Comment organiser la structure des rôles?
Comment fonctionne le stockage et la recherche des rôles?
Quelle est la différence entre import_role et include_role?
Comment exécuter un rôle plusieurs fois dans un playbook?
Conclusion
En maîtrisant les rôles Ansible, vous simplifiez la gestion de vos infrastructures. Comment envisagez-vous d’appliquer ces connaissances dans vos projets Ansible?