Gérer efficacement les données log complexes peut s’avérer fastidieux.
Sans une architecture solide, le traitement des logs devient inefficace, conduisant à des pertes de temps et de ressources.
L’architecture de Splunk, avec ses composants clés comme les forwarders et indexers, fournit une solution efficace pour une collecte et une analyse optimisées.
Maîtrisez les fonctionnalités de base dans l'analyse de logs avec Splunk

L’architecture de Splunk repose sur trois composants principaux : les forwarders , les indexers et les search heads . Chacun joue un rôle crucial dans le traitement et l’analyse des données log, assurant ainsi une collecte, un stockage et une recherche efficaces.
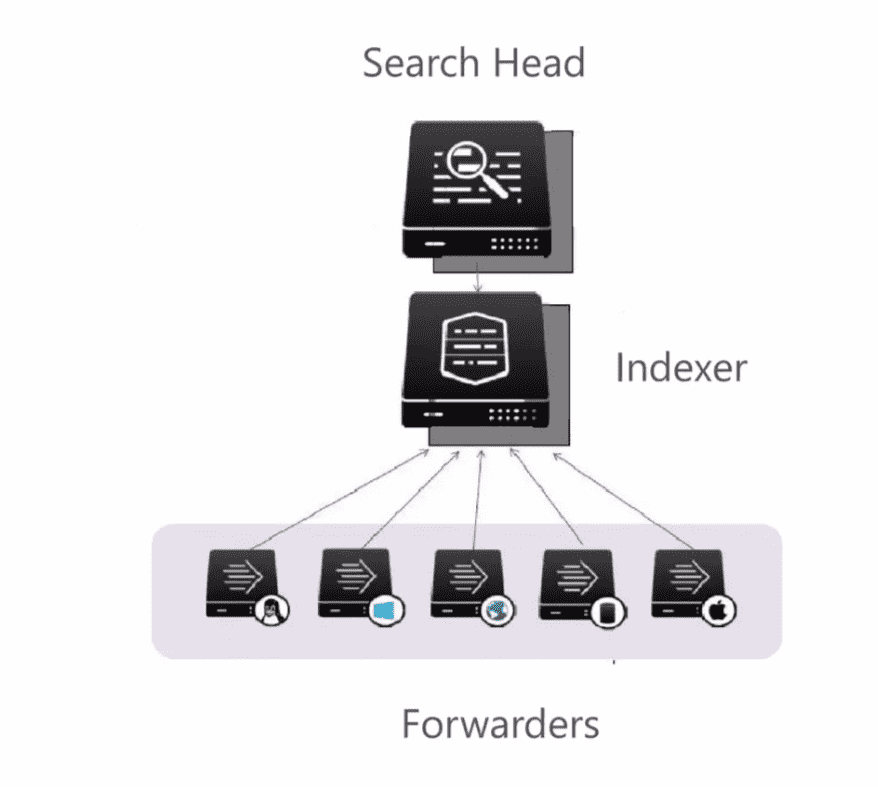
Forwarders dans l'Architecture Splunk
Le forwarder est installé sur un serveur web pour collecter des informations de session (comme l’adresse IP, l’état de connexion, le type de session) et les envoie à l’ indexeur .
L’indexeur reçoit ces données, les structure et les stocke pour faciliter leur analyse ultérieure.

- Web Server with Forwarder instance installed :Cela représente le forwarder, installé sur le serveur pour collecter les logs, comme expliqué dans le script. Ce forwarder envoie des informations de session (IP, statut de connexion, type de session) à un autre composant.
- Indexer :Dans le script, l’indexeur est décrit comme le composant qui reçoit les logs des forwarders pour les structurer et les stocker. Ici, l’indexeur est la destination des données collectées par le forwarder.
Indexers et ETL Splunk
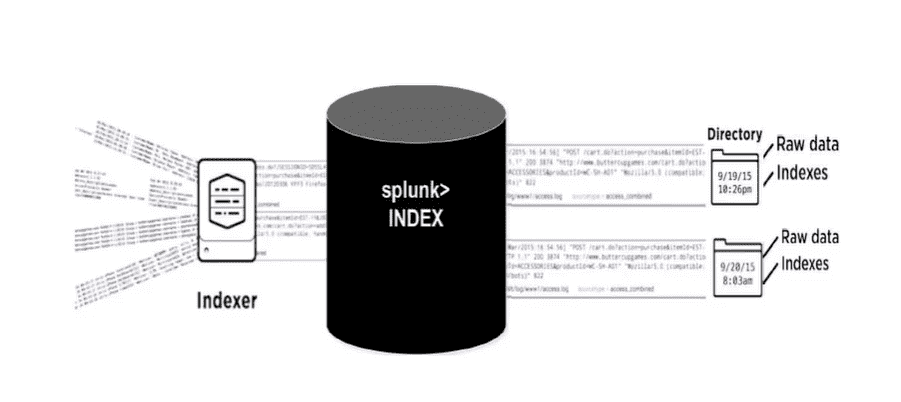
Le processus d’indexation se déroule en plusieurs étapes :
- Récupération des logs :soit via les Universal Forwarders, soit via des méthodes traditionnelles comme le syslog.
- Parsing et structuration :ici, les logs sont analysés et formatés pour extraire les informations essentielles (champs d’intérêt, dates, identifiants).
- Transformation et chargement (ETL) :ce processus, communément appelé ETL (Extract, Transform, Load), consiste à transformer les données en un format optimal avant de les stocker pour l’analyse.
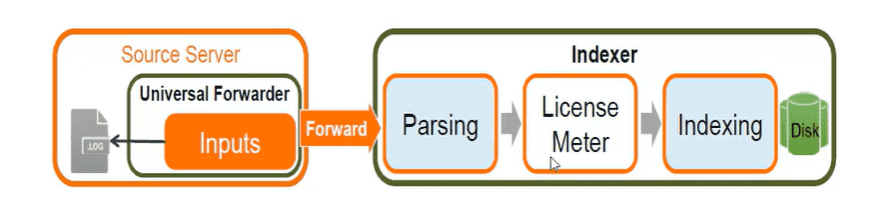

Search Heads pour Analyse Log
Le dernier composant de cette architecture est le searcher, qui permet aux utilisateurs d’interroger les données indexées grâce à un langage de recherche spécifique. Le searcher répartit les demandes de recherche entre les différents indexers et consolide les résultats. En plus, il fournit des outils pour affiner les recherches et offre des options de visualisation avancées (tableaux de bord, rapports).
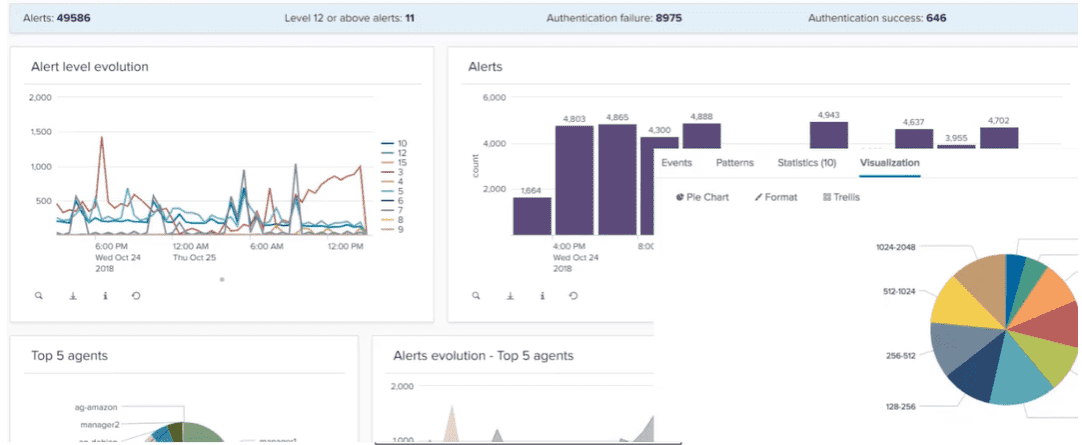
Les utilisateurs peuvent aussi créer des objets de recherche personnalisés pour extraire des informations spécifiques ou transformer des données sans affecter le contenu stocké dans les index.
Formez-vous gratuitement avec Alphorm !
Maîtrisez les compétences clés en IT grâce à nos formations gratuites et accélérez votre carrière dès aujourd'hui.

FAQ
Comment fonctionnent les forwarders dans Splunk?
Quel est le rôle des indexers dans l'architecture Splunk?
Comment les search heads facilitent-ils la recherche dans Splunk?
Qu'est-ce que le processus ETL dans Splunk?
Quels outils de visualisation offre Splunk?
Conclusion
L’architecture de Splunk offre une solution robuste pour l’analyse des données log. Comment pourriez-vous intégrer cette architecture dans votre environnement pour maximiser l’efficacité de vos analyses?