Les entreprises sont confrontées à l’explosion des Big Data, rendant leur gestion difficile sans une solution adaptée.
Ce problème entraîne une inefficacité dans le traitement des données, ralentissant la prise de décision et augmentant les coûts. Sans un système performant, ces volumes massifs deviennent ingérables.
Heureusement, l’écosystème Hadoop offre une solution puissante avec une architecture distribuée, permettant de traiter et analyser efficacement des données en temps réel.
Video | L’écosystème Hadoop
Dans cette vidéo, Noureddine DRISSI, expert en bases de données, vous introduira au monde du big data, en mettant l’accent sur l’écosystème Hadoop.
Cet article explore les composants clés d’Hadoop, comme Apache Spark, Hive, et HBase, qui répondent aux défis modernes des données massives.
Les enjeux du BIG DATA
Le Big Data a transformé la manière dont les entreprises collectent, stockent, et analysent les données. Avec des volumes de données qui ne cessent de croître, la gestion efficace de ces informations est devenue un enjeu crucial.
Les organisations doivent relever des défis en termes de traitement en temps réel, d’analyse de données massives, et d’optimisation des ressources.
C’est dans ce contexte que Hadoop s’impose comme une solution puissante et flexible, capable de traiter de grandes quantités de données de manière distribuée.
Maîtrisez la nouvelle manière de traitement des données sous Hadoop

Les composants Hadoop
Diagramme de l’écosystème Hadoop mettant en avant les composants clés :
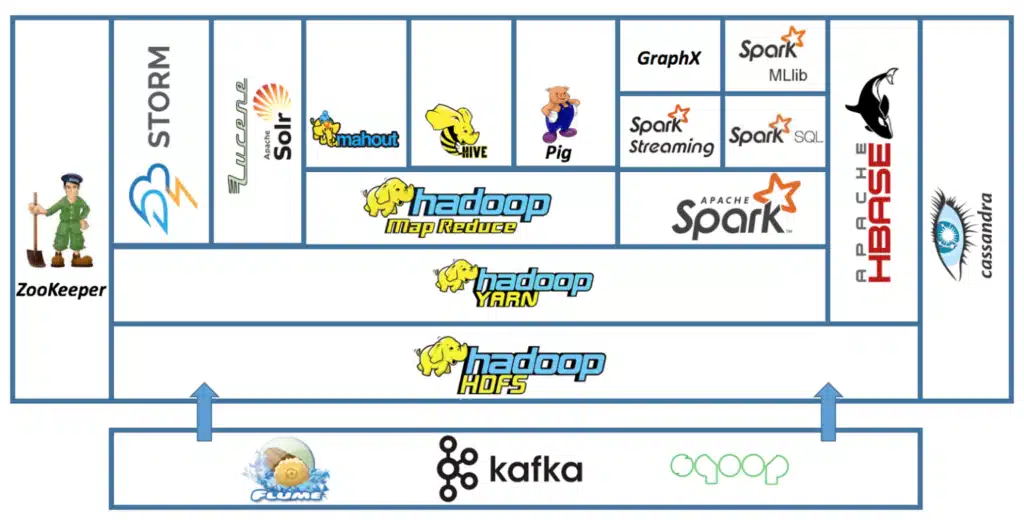
La plateforme Hadoop repose sur plusieurs composants clés :
HDFS (Hadoop Distributed File System)
Système de stockage distribué qui divise les fichiers en blocs et les stocke sur plusieurs machines pour assurer la redondance et la fiabilité.
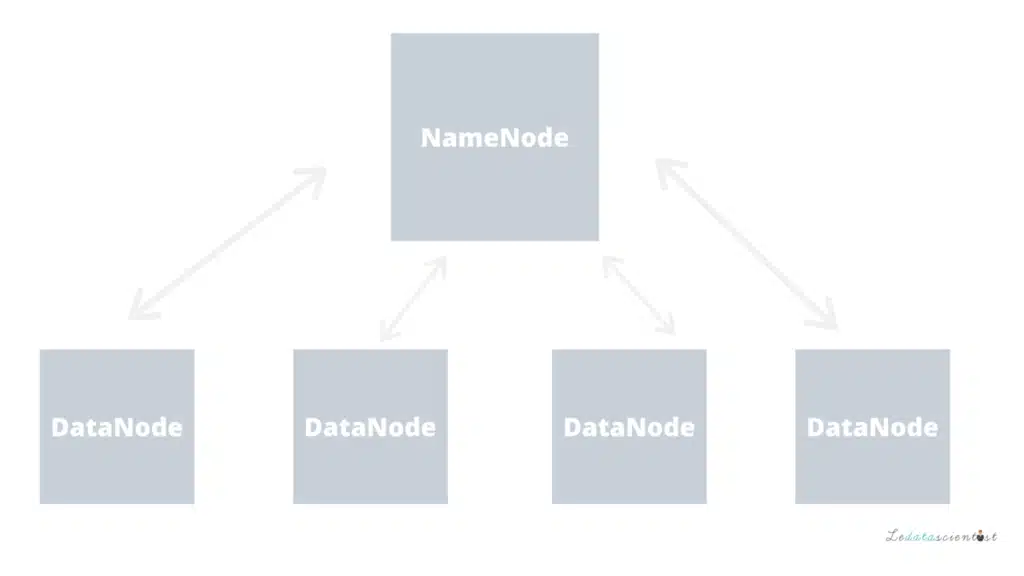
Le système de fichiers HDFS comporte deux composants principaux : le NameNode et les DataNodes.
- Le NameNode est le nœud (ou machine) principal, mais il ne stocke pas les données réelles.
Dans Hadoop, les données ne sont pas stockées au même endroit, elles sont même fragmentées en morceaux et dupliquées.
Le rôle du NameNode est donc de savoir à tout moment où ces données sont localisées. En d’autres termes, il conserve les métadonnées concernant les machines (ou nœuds) où se trouvent réellement les données. Cela signifie qu’il requiert moins d’espace de stockage, mais demande davantage de ressources en calcul. - De l’autre côté, comme vous l’avez probablement deviné, il y a les DataNodes. Ceux-ci sont responsables du stockage des données et nécessitent donc plus de ressources de stockage.
MapReduce
Modèle de programmation qui permet le traitement parallèle de grandes quantités de données.
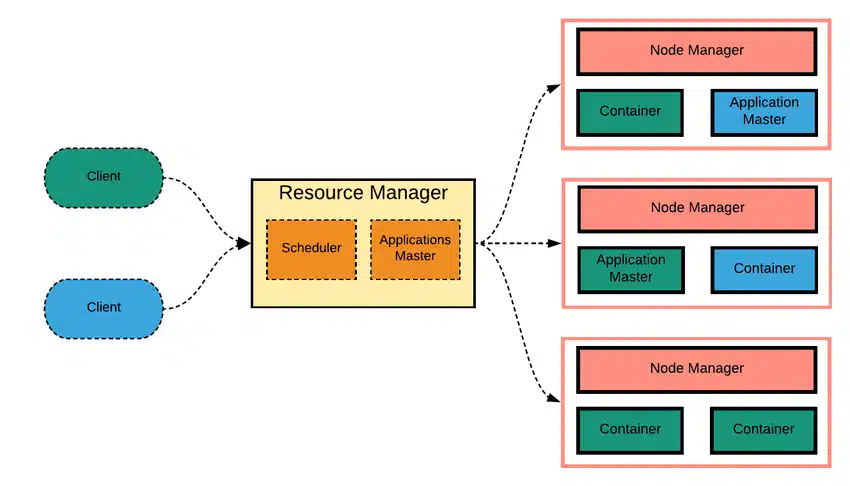
YARN (Yet Another Resource Negotiator)
Outil de gestion des ressources qui permet d’optimiser l’allocation des tâches au sein du cluster Hadoop.
Schéma de l’architecture d’Apache Hadoop YARN montrant les interactions entre les clients, le Resource Manager et plusieurs Node Managers, chacun gérant des containers et des Application Masters.
Ces trois composants forment le socle du système Hadoop, mais l’écosystème a évolué avec l’ajout de nombreux outils pour répondre à des besoins spécifiques en matière de traitement de données.
L’écosystème Hadoop
L’écosystème Hadoop comprend une série d’outils complémentaires qui permettent d’étendre ses capacités, chacun étant conçu pour répondre à des besoins particuliers du Big Data. Voici un tour d’horizon des principaux composants :
- Apache Spark : une plateforme de traitement de données en temps réel qui dépasse les limites de MapReduce en termes de rapidité. Utilisé pour des analyses de données complexes comme le machine learning ou les analyses prédictives, Spark est un incontournable dans l’écosystème Hadoop.
- Apache Hive : permet de requêter des données dans Hadoop à l’aide d’un langage SQL. Il transforme les requêtes SQL en jobs MapReduce, permettant aux utilisateurs ayant une expérience en SQL de manipuler des données massives sans connaître les détails de MapReduce.
- Apache Pig : un outil qui facilite le traitement des données volumineuses grâce à un langage de script (Pig Latin). Il est plus simple d’utilisation que MapReduce, offrant une alternative pour les utilisateurs qui souhaitent automatiser des tâches complexes avec moins de code.
- HBase : une base de données NoSQL distribuée conçue pour traiter des millions d’enregistrements en temps réel. Elle s’intègre parfaitement dans l’écosystème Hadoop pour fournir un stockage rapide et évolutif.
- Sqoop : est utilisé pour transférer des données entre Hadoop et des bases de données relationnelles comme MySQL, PostgreSQL ou Oracle. Il permet d’importer et d’exporter des données volumineuses entre différents environnements.
- Apache Storm : une plateforme de traitement des flux en temps réel, idéale pour des cas d’usage comme la surveillance des réseaux sociaux, le traitement de capteurs ou l’analyse en temps réel. Il permet d’ingérer, de traiter et de produire des résultats en temps réel sans délai.
- Zookeeper : un service de coordination essentiel pour la gestion des clusters Hadoop. Il assure la synchronisation et la coordination des différentes applications et services distribués, garantissant la stabilité et la fiabilité des environnements Hadoop.
- Oozie: un système de gestion de workflows conçu pour planifier et automatiser des jobs dans Hadoop. Il permet de gérer et d’orchestrer les jobs Spark, Hive, et MapReduce de manière efficace, facilitant ainsi l’automatisation des processus de traitement des données.
Conclusion
L’écosystème Hadoop offre une large gamme d’outils qui permettent de traiter et d’analyser des données massives avec efficacité. Que ce soit pour l’analyse en temps réel avec Spark, l’importation de données avec Sqoop ou la gestion des workflows avec Oozie, chaque composant joue un rôle spécifique dans la gestion des Big Data.